
Упорядоченные поколоночные индексы в SQL Server 2022
Пересказ статьи Edward Pollack. Ordered Columnstore Indexes in SQL Server 2022
Одним из наиболее сложных технических моментов поколоночных индексов, который постоянно привлекает внимание, является необходимость упорядочивания данных для устранения сегментации. В некластеризованном поколоночном индексе порядок данных устанавливается автоматически на основе построчного порядка базовых данных. Однако в кластеризованном поколоночном индексе порядок данных не навязывается каким-либо процессом SQL Server. Это управление порядком данных остается на наше усмотрение, что может не оказаться (или оказаться) легкой задачей.
Чтобы помочь с этой проблемой, в SQL Server 2022 была добавлена возможность указывать предложение ORDER при создании или перестройке индекса. Эта функция приводит к автоматической сортировке данных SQL Server в рамках процессов вставки или перестройки. В этой статье подробно рассматривается эта функция, уделяя внимание ее использованию и ограничениям.
Краткий обзор порядка данных
Чтобы полностью оценить влияние порядка данных на поколоночный индекс, будет представлена небольшая демонстрация воздействия упорядочивания на устранение сегментации и, в конечном итоге, влияния на производительность.
Следующий код T-SQL создает таблицу с поколоночным индексом и вставляет в нее ~ 7,1 миллиона строк (этот скрипт использует базу данных WideWorldImportersDW. Вы можете загрузить эту базу данных здесь):
CREATE TABLE dbo.fact_order_BIG_CCI (
[Order Key] [bigint] NOT NULL,
[City Key] [int] NOT NULL,
[Customer Key] [int] NOT NULL,
[Stock Item Key] [int] NOT NULL,
[Order Date Key] [date] NOT NULL,
[Picked Date Key] [date] NULL,
[Salesperson Key] [int] NOT NULL,
[Picker Key] [int] NULL,
[WWI Order ID] [int] NOT NULL,
[WWI Backorder ID] [int] NULL,
[Description] [nvarchar](100) NOT NULL,
[Package] [nvarchar](50) NOT NULL,
[Quantity] [int] NOT NULL,
[Unit Price] [decimal](18, 2) NOT NULL,
[Tax Rate] [decimal](18, 3) NOT NULL,
[Total Excluding Tax] [decimal](18, 2) NOT NULL,
[Tax Amount] [decimal](18, 2) NOT NULL,
[Total Including Tax] [decimal](18, 2) NOT NULL,
[Lineage Key] [int] NOT NULL);
-- Генерируем 7,173,772 строк в куче
INSERT INTO dbo.fact_order_BIG_CCI
SELECT
[Order Key] + (250000 * ([Day Number] +
([Calendar Month Number] * 31))) AS [Order Key]
,[City Key]
,[Customer Key]
,[Stock Item Key]
,[Order Date Key]
,[Picked Date Key]
,[Salesperson Key]
,[Picker Key]
,[WWI Order ID]
,[WWI Backorder ID]
,[Description]
,[Package]
,[Quantity]
,[Unit Price]
,[Tax Rate]
,[Total Excluding Tax]
,[Tax Amount]
,[Total Including Tax]
,[Lineage Key]
FROM Fact.[Order]
CROSS JOIN
Dimension.Date
WHERE Date.Date <= '2013-01-31';
-- Создаем поколоночный индекс на таблице.
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI
ON dbo.fact_order_BIG_CCI;Не выполнено никакой оптимизации или принято предположений относительно порядка данных. Это поколоночный индекс, находящийся поверх кучи данных как есть. Здесь можно будет сделать предположение, что эти данные будут наиболее часто выбираться поиском по дате. Если так, то идеальным было бы упорядочивание данных по столбцу
Order Date Key. Чтобы проверить порядок строк относительно Order Date Key, можно использовать следующий запрос, показывающий максимальное и минимальное значение для столбца в пределах каждой группы строк:SELECT
tables.name AS table_name,
indexes.name AS index_name,
columns.name AS column_name,
partitions.partition_number,
column_store_segments.segment_id,
column_store_segments.min_data_id,
column_store_segments.max_data_id,
column_store_segments.row_count
FROM sys.column_store_segments
INNER JOIN sys.partitions
ON column_store_segments.hobt_id = partitions.hobt_id
INNER JOIN sys.indexes
ON indexes.index_id = partitions.index_id
AND indexes.object_id = partitions.object_id
INNER JOIN sys.tables
ON tables.object_id = indexes.object_id
INNER JOIN sys.columns
ON tables.object_id = columns.object_id
AND column_store_segments.column_id = columns.column_id
WHERE tables.name = 'fact_order_BIG_CCI'
AND columns.name = 'Order Date Key'
ORDER BY tables.name, columns.name, column_store_segments.segment_id;Результаты показаны ниже (ваши результаты должны быть похожи, но могут слегка отличаться - это нормально. В некоторых прогонах у меня было создано дополнительное разбиение):
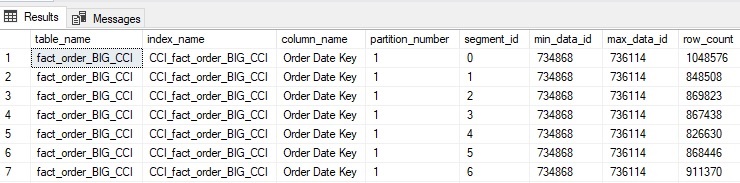
Каждая строка вывода является отдельной группой строк в пределах поколоночного индекса. Заметим, что для каждой группы строк min_data_id и max_data_id одинаковы. Это говорит о том, что данные не упорядочены, и один и тот же набор различных значений разбросан по всем группам строк. Влияние этого факта может быть проиллюстрировано выполнением простого аналитического запроса:
SET STATISTICS IO ON; --Вывод IO, который потребовался для выполнения запроса
SELECT SUM([Total Excluding Tax]) AS [Total Excluding Tax]
FROM dbo.fact_order_BIG_CCI
WHERE [Order Date Key] = '2014-12-04';Этот запрос возвращает сумму только для отдельного значения даты. После выполнения на выходе получена следующая статистика по вводу/выводу:
Table 'fact_order_BIG_CCI'. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 1540, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'fact_order_BIG_CCI'. Segment reads 8, segment skipped 0.Заметьте, что прочитано было 8 сегментов и пропущено - 0. Это говорит о том, что данные должны были читаться из всех групп строк для того, чтобы вернуть информацию для единственной даты. Количество чтений (1547) также подозрительно велико для такого простого запроса.
Следующий шаг демонстрации - упорядочить эти данные и повторно выполнить вышеприведенные запросы.
Для этого поколоночный индекс будет заменен на кластеризованный построчный индекс, который упорядочивается по Order Date Key. Кластеризованный построчный индекс будет затем заменен на кластеризованный поколоночный индекс. MAXDOP = 1 гарантирует, что параллелизм случайно не приведет к неупорядоченным данным из-за перемешивания в нескольких потоках упорядоченных данных в новые группы строк (Кластеризованный индекс, который я создаю первым, упорядочивает данные в объекте до создания кластеризованного поколоночного индекса):
CREATE CLUSTERED INDEX CCI_fact_order_BIG_CCI
ON dbo.fact_order_BIG_CCI ([Order Date Key]) WITH (DROP_EXISTING = ON);
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI
ON dbo.fact_order_BIG_CCI WITH (DROP_EXISTING = ON, MAXDOP = 1);Повторное выполнение запроса к метаданным групп строк возвращает следующее:
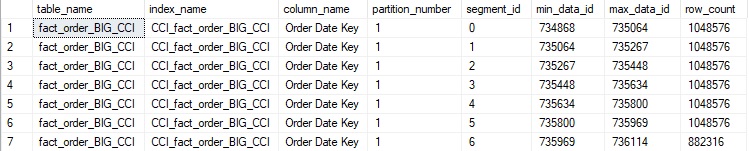
Минимальное и максимальное значения для Order Date key теперь прекрасно упорядочиваются от наименьшего к наибольшему значениям. Выполнение прошлого простого аналитического запроса дает следующую статистику ввода-вывода:
Table 'fact_order_BIG_CCI'. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 388, lob physical reads 0, lob page server reads 0, lob read-ahead reads 836, lob page server read-ahead reads 0.
Table 'fact_order_BIG_CCI'. Segment reads 1, segment skipped 6.Только 1 сегмент был прочитан и 6 - пропущены. Заметьте, что логических операций ввода-вывода стало меньше чем прежде примерно в 10 раз!
Фильтрация больших наборов данных OLAP на упорядоченных данных поколоночного хранения будет значительно быстрей и более эффективной, чем несортированных данных. Но как обычно упорядочиваются данные на протяжении всего срока службы таблицы? Наиболее общим решением является следующее:
- Структурируйте аналитическую таблицу так, чтобы она допускала только операции вставки и удаления.
- Всячески избегайте обновлений.
- Вставляйте новые данные в конец таблицы для самого последнего измерения даты.
В противном случае, если большую таблицу необходимо преобразовать в поколоночный индекс, то необходим трюк, продемонстрированный выше, с упорядочиванием построчного индекса и заменой на поколоночный индекс поверх заново упорядоченной таблицы.
Введение: упорядоченные индексы поколоночного хранения!
SQL Server 2022 добавил предложение ORDER в синтаксис создания кластеризованного поколоночного индекса. В нем указывается, какие столбцы поколоночных данных сортировать в рамках операции перестройки или операции INSERT.
Для изменения нашего существующего поколоночного индекса для использования этой возможности, можно использовать следующий синтаксис:
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI
ORDER ([Order Date Key])
WITH (DROP_EXISTING = ON, MAXDOP = 1);Результат этого изменения формализует порядок поколоночного индекса по умолчанию с использованием Order Date Key. Когда оператор создания поколоночного индекса включает ключевое слово ORDER, SQL Server будет сортировать данные в TempDB на основе указанных столбцов. Кроме того, при вставке новых данных в поколоночный индекс он также будет предварительно отсортирован. Если упорядоченный кластеризованный индекс подвергается операции перестройки, будет поддерживаться указанный ранее порядок.
Эта функциональность звучит как идеальное решение, чтобы сделать возможным устранение сегментации, но это не обходится даром. Как и подразумевает слово СОРТИРОВКА, SQL Server требуется привлекать ресурсы для сортировки данных. Это не только требование к ресурсам TempDB, но и оффлайн операция. Следовательно, переход кластеризованного поколоночного индекса к сортированному приведет к операциям перестройки с переводом из онлайн к оффлайн операциям. Заметьте, что в секционированной таблице операция будет выполняться в оффлайн только для секций, подверженных операции перестройки. Обычно это бывает единственная секция с текущими данными. Тем самым секционирование может помочь улучшить доступность большинства данных в упорядоченных кластерированных поколоночных индексах.
Операцию сортировки можно визуализировать проверкой плана выполнения как для стандартного, так и упорядоченного поколоночного индекса.
Если мы посмотрим план выполнения для создания трех индексов, то увидим некоторые интересные различия. Следующий план построен для создания неупорядоченного поколоночного индекса, построенного ранее в этой статье:
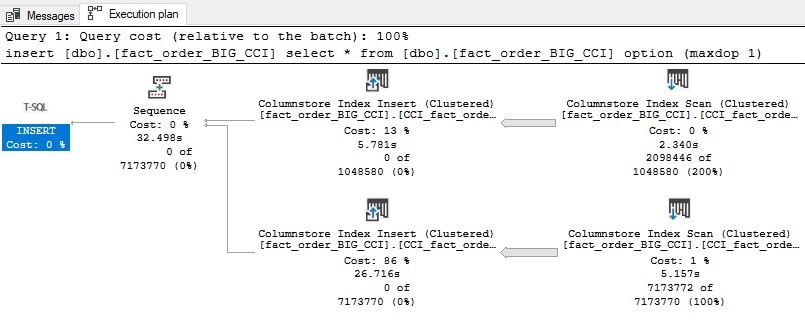
Ничего удивительного. Я пождал 30 секунд, и поколоночный индекс готов для использования на таблице. Использование нового синтаксиса, который включает предложение ORDER, произведет следующий план выполнения:
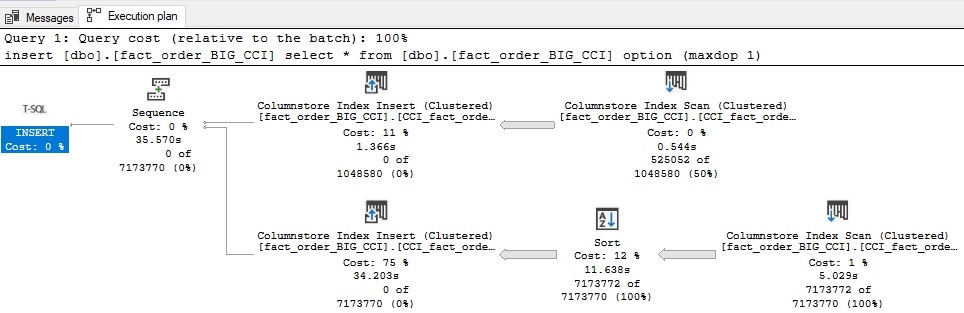
В плане появляется операция SORT. Без секционирования или других вспомогательных вещей SQL Server требуется отсортировать весь набор данных для того, чтобы создать индекс, который упорядочен по выбранному мной столбцу.
Использованные в предложении ORDER столбцы можно всегда проверить с помощью системного представления sys.index_columns, используя подобный запрос:
SELECT
tables.name AS table_name,
indexes.name AS index_name,
columns.name AS column_name,
index_columns.column_store_order_ordinal
FROM sys.index_columns
INNER JOIN sys.indexes
ON indexes.index_id = index_columns.index_id
AND indexes.object_id = index_columns.object_id
INNER JOIN sys.columns
ON index_columns.object_id = columns.object_id
AND columns.column_id = index_columns.column_id
INNER JOIN sys.tables
ON tables.object_id = indexes.object_id
WHERE tables.name = 'fact_order_BIG_CCI';Список результатов по всем столбцам таблицы наряду с их порядком поколоночного хранения, если применимо. Значение нуль указывает на то, что столбец не является частью поколоночного упорядочивания:
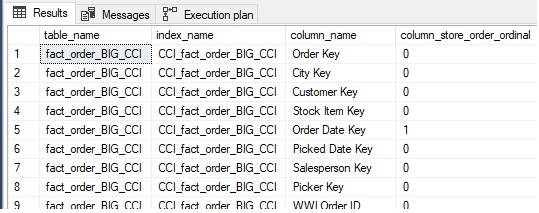
Метаданные показывают, что Order Date Key является единственным столбцом в предложении ORDER для этого поколоночного индекса. Рассмотрим новый индекс, упорядоченный по Order Date Key, а затем по Order Key:
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI
ORDER ([Order Date Key], [Order Key])
WITH (DROP_EXISTING = ON, MAXDOP = 1);Для этого индекса результаты метаданных показывают дополнительный столбец в поколоночном порядке столбцов:
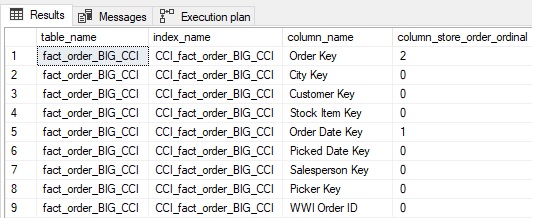
Заметьте, что Order Key теперь показан вторым столбцом в поколоночном порядке после Order Date Key. Для большой таблицы с поколоночным индексом упорядочение по дополнительному столбцу может дополнительно помочь в запросах, использующих фильтры из нескольких столбцов.
Замечания и соображения по упорядоченному поколоночному индексу
Важно напомнить, что только кластеризованные поколоночные индексы могут быть использованы с предложением ORDER. Некластеризованные поколоночные индексы при создании наследуют порядок данных базовой структуры построчного индекса и будут настолько обеспечивать эффективность исключения сегментов, насколько это позволяют базовые данные.
Упорядоченные поколоночные индексы являются тяжеловесным и в чем-то несовершенным способом улучшения порядка данных и исключения сегментов по трем причинам:
- Перестройка упорядоченного поколоночного индекса является оффлайновой операцией.
- Любые сортируемые данные должны сортироваться в TempDB.
- Если операция сортировки настолько велика, что сбрасывается на диск, то сортировка прерывается и порядок данных может не быть совершенным.
Имеет смысл изучить каждую из этих проблем, чтобы гарантировать, что решения, принимаемые в отношении упорядоченных поколоночных индексов, являются наиболее оптимальными:
Перестройка упорядоченного поколоночного индекса является оффлайновой операцией (по секциям)
Это проблема доступности, которая не затронет всех пользователей поколоночных индексов. Если для обслуживания индекса существуют специальные окна обслуживания, а для операций перестроения применим режим ОФФЛАЙН, то здесь проблем не возникает. Реорганизация индекса по-прежнему выполняется в режиме ОНЛАЙН и может использоваться как часть регулярного обслуживания, чтобы уменьшить необходимость в перестроениях.
Количество времени, в течение которого секция будет недоступна, равна количеству времени, необходимому на сортировку и перестройку данных в этой секции. Следовательно, если перестройка секции в 20 миллионов строк в кластеризованном поколоночном индексе обычно занимает 30 секунд, тогда та же операция приведет как минимум к 30-секундному отключению/простою для того же индекса, если бы он был упорядочен. Предположительно операция сортировки потребует некоторого дополнительного времени, увеличивая общее время до некоторого числа, превышающего 30 секунд.
Возможно использование переключения секций для повышения доступности, хотя, желателен ли такой уровень дополнительной сложности или нет, решать вам.
Упорядоченные поколоночные индексы сортируются в TempDB
Данные требуется сортировать, и TempDB в SQL Server - это то место, где это происходит. Таким образом, чтобы гарантировать надлежащую сортировку данных, важно, чтобы для TempDB было выделено достаточно места. Если 500Мб данных требуется вставить в уполрядоченный поколоночный индекс, тогда необходимо иметь дополнительно 500Мб доступного пространства в TempDB.
Аналогично, если поколоночный индекс размером 500Мб перестраивается в упорядоченный поколоночный индекс, то потребуется 500Мб+ пространства в TempDB, в зависимости от организации и железа.
Если в TempDB недостаточно свободного пространства для сохранения приходящих поколоночных данных, тогда не используйте эту функциональность. Хотя гарантия достаточного пространства становится более важной из-за следующецй проблемы:
Операции сортировки не завершаются полностью
Что происходит, когда упорядоченный поколоночный индекс перестраивается или в него вставляются данные, а в TempDB недостаточно места? Не то, что вы ожидали! Обычно, если оператор сортировки в плане выполнения требует больше пространства TempDB, чем выделено или имеется в наличии, он сбрасывает данные на диск, чтобы выделить достаточно пространства для завершения операции.
Это НЕ ТО, что происходит с упорядоченными поколоночными индексами. Если данные, для которых требуется выполнить сортировку в упорядоченном поколоночном индексе, превышают объем выделенной памяти, то операция сортировки просто завершается и внутри устанавливается флажок soft sort (мягкая сортировка). Мягкая сортировка отсортирует столько строк, сколько сможет, но когда пространство заканчивается, она останавливается. Хотя такое поведение гарантирует, что операции записи выполняются быстро и не сбрасываются на диск, оно также представляет опасность, поскольку без дальнейших исследований не сразу ясно, имело ли оно место.
Для иллюстрации мягкой сортировкиранее используемая тестовая таблица будет удалена, создана заново и заполнена ~27.8 миллионами строк. Также будет относительно уменьшен размер TempDB, чтобы обеспечить недостаток места для полной сортировки этих данных. Следующий код выполняет удаление таблицы, создание и наполнение данными:
DROP TABLE dbo.fact_order_BIG_CCI;
CREATE TABLE dbo.fact_order_BIG_CCI (
[Order Key] [bigint] NOT NULL,
[City Key] [int] NOT NULL,
[Customer Key] [int] NOT NULL,
[Stock Item Key] [int] NOT NULL,
[Order Date Key] [date] NOT NULL,
[Picked Date Key] [date] NULL,
[Salesperson Key] [int] NOT NULL,
[Picker Key] [int] NULL,
[WWI Order ID] [int] NOT NULL,
[WWI Backorder ID] [int] NULL,
[Description] [nvarchar](100) NOT NULL,
[Package] [nvarchar](50) NOT NULL,
[Quantity] [int] NOT NULL,
[Unit Price] [decimal](18, 2) NOT NULL,
[Tax Rate] [decimal](18, 3) NOT NULL,
[Total Excluding Tax] [decimal](18, 2) NOT NULL,
[Tax Amount] [decimal](18, 2) NOT NULL,
[Total Including Tax] [decimal](18, 2) NOT NULL,
[Lineage Key] [int] NOT NULL);
-- Генерация 27769440 строк в куче:
INSERT INTO dbo.fact_order_BIG_CCI
SELECT
[Order Key] + (250000 * ([Day Number] +
([Calendar Month Number] * 31))) AS [Order Key]
,[City Key]
,[Customer Key]
,[Stock Item Key]
,[Order Date Key]
,[Picked Date Key]
,[Salesperson Key]
,[Picker Key]
,[WWI Order ID]
,[WWI Backorder ID]
,[Description]
,[Package]
,[Quantity]
,[Unit Price]
,[Tax Rate]
,[Total Excluding Tax]
,[Tax Amount]
,[Total Including Tax]
,[Lineage Key]
FROM Fact.[Order]
CROSS JOIN
Dimension.Date
WHERE Date.Date <= '2013-04-30'; При данных в куче, ожидающих сортировки, будет включен флаг трассировки 8666:
DBCC TRACEON (8666);Этот недокументированный флаг трассировки предоставит дополнительную информацию оптимизатора запросов, которая, в противном случае, будет отсутствовать в плане запроса (графическом или XML). Если вы экспериментируете с этим флагом трассировки, убедитесь, что работаете в тестовой среде, и выключите флажок, когда закончите тестирование!
При наличии добавленной информации оптимизатора давайте включим фактический план выполнения, тогда мы сможем быстро визуализировать, что здесь происходит:
Наконец, пора построить упорядоченный поколоночный индекс на большой таблице, созданной выше:
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI
ORDER ([Order Date Key], [Order Key])
WITH (MAXDOP = 1)Это занимает несколько минут на моем локальном сервере. План выполнения теперь содержит некоторую дополнительную информацию, которую можно использовать для понимания происходящего, когда SQL Server сортирует поступающие данные:
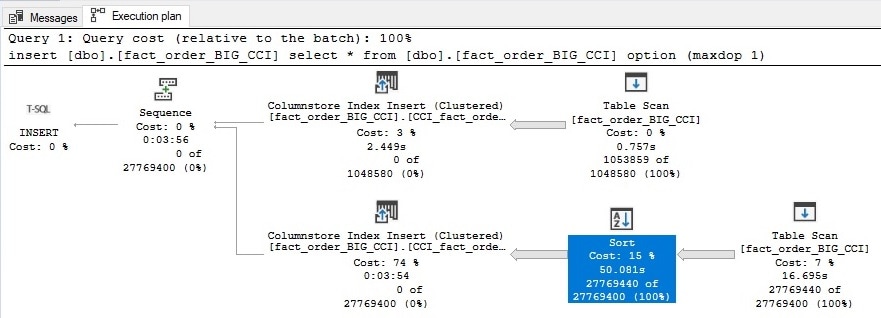
Переход к свойствам оператора Sort позволяет нам получить некоторую дополнительную информацию:
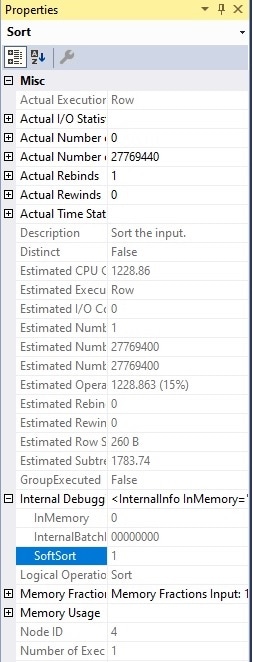
Среди внутренней информации отладчика находится флаг, который указывает, имела место мягкая сортировка или нет. В данном случае ответ да!
После этой проверки будет выполнен запрос метаданных, приведенный ранее в этой статье, чтобы показать, насколько хорошо упорядочены группы строк в поколоночном индексе:
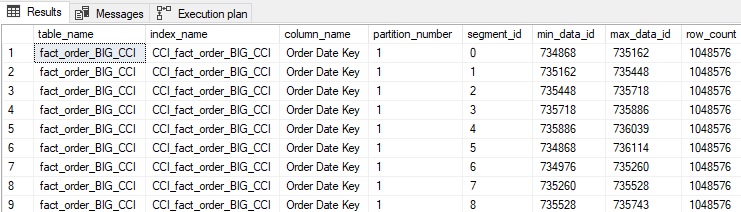
Всего имеется 27 групп строк, но ясно из первых 9, что эти данные фактически не упорядочены по Order Date Key как следовало. Рассмотрение данных min_data_id и max_data_id показывает НЕКОТОРОЕ упорядочение; очевидно, что запрос, который должен прочитать 1-2 группы строк, будет вместо этого читать много больше, т.к. многие диапазоны значений переклываются.
Подытоживая: мягкая сортировка представляет собой опасность для построения и обслуживания упорядоченных поколоночных индексов и может оказаться причиной, чтобы отложить их использование до тех пор, пока функция не будет усовершенствована.
Заключение
До появления этой функциональности порядок поддерживался вручную. Это звучит тревожно, но в реальности аналитические данные часто создаются на основе даты/времени и упорядочиваются естественным образом на базе некоторого ключевого измерения (измерений), зачастую даты/времени.Например, таблица, которая загружает ежедневно новые данные по продажам, будет добавлять данные нового дня в конец поколоночного индекса каждый день. Поэтому, если обновления не выполняются на этой таблице, то данные будут сохранять естественный порядок, т.к. новые данные будут также самыми свежими. Даже если 5% поступающих данных были старыми и выпадали из порядка, общее исключение сегментов должно быть по-прежнему достаточно хорошим.
Упорядоченные поколоночные индексы представляют собой попытку сосредоточиться на исключении групп строк с целью ускорения аналитических запросов. Если поколоночный индекс содержит 1 миллиард строк, то он будет содержать примерно 1000 групп строк. Чтение 1000 сегментов для получения данных по одному столбцу существенно дороже, чем чтение 3 сегментов. Несмотря на обещания, упорядоченные поколоночные индексы не являются совершенными и имеют ограничения, которые делают их далеко не идеальным решением, особенно для таблиц с большим количеством регулярно вставляемых или перестраиваемых данных.
Эта функциональность может у вас работать, но проведите тесты и убедитесь, что операции вставки или перестройки на самом деле корректно сортируют данные. В противном случае, возможно, лучше будет вернуться к старомодному способу управления этими данными, используя естественное упорядочивание посредством процессов, выполняемых вручную.
Давайте будем надеяться на улучшение этой функциональности! Поколоночные индексы являются ярким примером функциональности, постоянно улучшаемой с каждой новой версией SQL Server, начиная с их появления. Точно так же, как поколоночные индексы совершенствовались, чтобы обеспечить более широкое разнообразие операций записи, исключения групп строк для большего числа типов данных, предикатов и улучшенной консолидации/обслуживания групп строк, вероятно, что эта функциональность также скоро получит столь необходимое обновление.
Ссылки по теме
1. Все, что вам нужно знать о поколоночных индексах, в одной статье
2. Поколоночные индексы - что это?
3. Кучи в SQL Server: часть 1 - основы
4. Освоение TempDB: основы
5. Введение в план выполнения SQL Server
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой