
Шесть вещей для мониторинга в PostgreSQL
Пересказ статьи Ryan Booz. Six Things to Monitor with PostgreSQL
В этой статье описываются шесть метрик производительности, которые должны быть на первом месте вашей стратегии мониторинга PostgreSQL. Используя инструмент, подобный SQL Monitor, для отслеживания этих метрик во времени и устанавливая для них базовые линии, вы сможете сразу выявлять нехватку ресурсов или проблемы с производительностью, быстро диагностируя причину и предотвращая возникновение проблем для пользователей.
PostgreSQL продолжает развиваться как в сторону расширения рынка, так и общей популярности среди разработчиков. Частично это обусловлено очень либеральной лицензией на продукт с открытыми кодами, 25+ годами основания технологии и беспрецедентными возможностями расширения. Вот почему так много разработчиков и предприятий выбирают PostgreSQL.
Для некоторых администраторов БД, которые имеют большой опыт работы на другой платформе, как-то SQL Server, понимание мониторинга базы данных для достижения пиковой производительности может поначалу показаться сложным. Из-за природы продукта с открытым кодом проблема проактивного мониторинга пока не решена в экосистеме PostgreSQL. PostgreSQL имеет много метрик, которые могут обеспечить понимание текущего состояния базы данных или сервера, но автоматизированный согласованный мониторинг не встроен в ядро продукта с открытым кодом.
Чтобы получить максимум от платформы, важно иметь инструменты, которые могут легко получить эти метрики и помочь вам осмыслить цифры в данный момент и с течением времени. SQL Monitor собирает широкий набор тех метрик для PostgreSQL, которые предназначены, чтобы помочь вам идентифицировать и диагностировать все общие причины падения производительности или проблемы обслуживания в базах данных PostgreSQL. В этой статье мы обсудим шесть из этих метрик PostgreSQL, которые следует постоянно отслеживать на уровне сервера и базы данных, чтобы обеспечить гладкую работу и показать вам, как SQL Monitor готов помочь вам в этом.
Нет ничего хуже, чем иметь медленно выполняющийся запрос в приложении и не иметь возможности понять почему. Некоторые базы данных имеют функции, которые помогают вам идентифицировать, почему производительность запроса изменилась с течением времени для отдельных запросов (например, функционал хранилища запросов, Query Store, в SQL Server).
PostgreSQL, с другой стороны, пока не обладает встроенными процессами или компонентами, которые автоматически делали бы это за вас. Хотя существует много необходимых метрик, и они поддерживаются на всех версиях PostgreSQL, мониторинг медленно выполняющихся запросов по-прежнему возлагается на конечного пользователя.
При правильном конфигурировании все поддерживаемые версии PostgreSQL собирают статистику о выполнении каждого запроса, если расширение pg_stat_statements установлено и доступно для, по крайней мере, одной базы данных в кластере. Сейчас PostgreSQL сохраняет только накопительные общие значения метрик для каждого запроса, и вы найдете много инструментов онлайн и тестовых запросов, которые покажут вам средние значения для конкретного запроса. Однако пока вы не захватываете и не сохраняете "снимки" этих данных, у вас не будет способа идентифицировать, какой запрос влияет на производительность сервера прямо сейчас, или в какой-то момент времени в прошлом, или понять, деградировала ли производительность конкретного запроса внезапно или постепенно с течением времени.
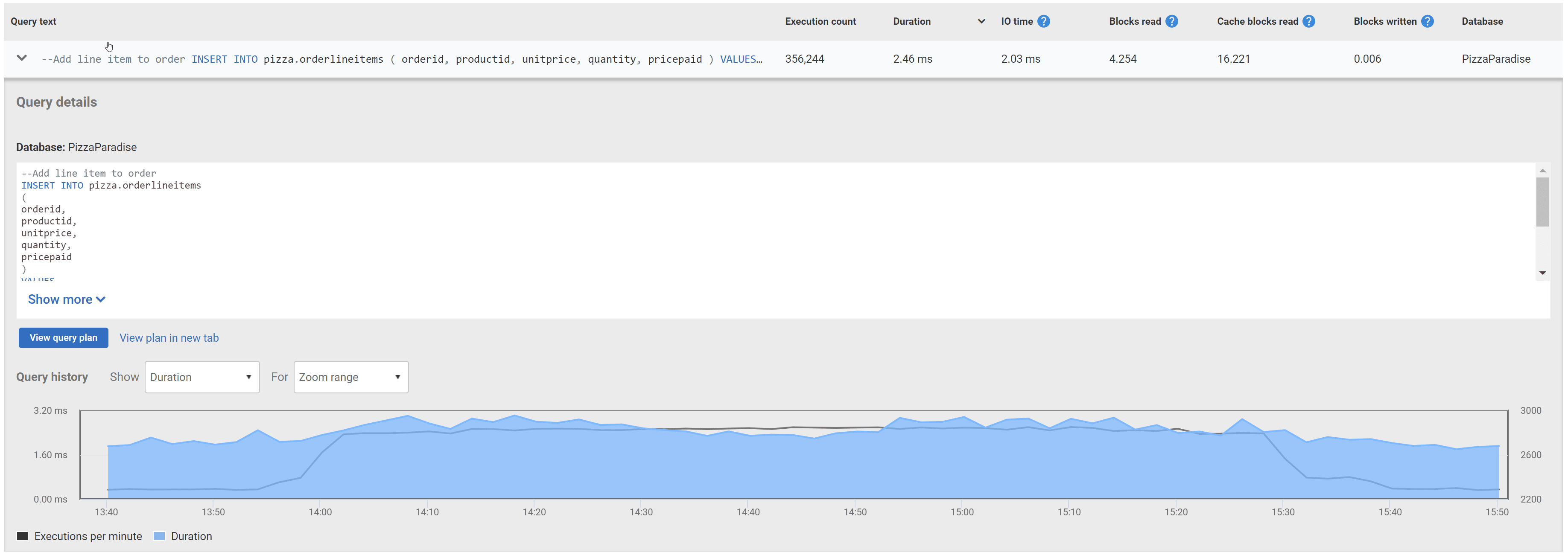
Вот где инструмент типа SQL Monitor может быть особенно полезен, поскольку он будет автоматически отслеживать статистику производительности этих запросов, значительно облегчая обнаружение проблем. Предполагая, что pg_stat_statements установлено, SQL Monitor будет периодически извлекать данные и сохранять снимки статистики. Он выводит эти данные в разделе Top Queries (топовые запросы) обзора сервера (Server Overview), что делает много проще как идентификацию наиболее дорогих запросов, которые выполняются в период падения производительности, так и понять тенденцию в производительности запроса в течение времени.
Раздел Top Queries позволяет вам быстро фильтровать наиболее дорогие запросы на основе определенных характеристик. Эта область фильтруется по тому же самому диапазону времени, что и страница с общими метриками сервера, помогая пользователям сфокусировать усилия на исследовании.
В пределах этого диапазона времени вы можете сортировать топовые запросы на основе средних или общих метрических значений по любым отслеживаемым метрикам. Например, если производительность сервера упала за последний час, часто полезно посмотреть, какие запросы выполнялись чаще или имели наибольшее среднее время выполнения. Панель подробной информации, открываемая для любого запроса в списке, покажет полный текст запроса и историю среднего числа выполнений и их продолжительность во времени.
Идентифицировав дорогой запрос или тот, который кажется выполняется ненормально, план запроса часто поможет нам понять, почему это происходит. Однако упреждающий захват планов запросов не происходит автоматически в PostgreSQL. Напротив, он требует расширения auto_explain, и планы запросов сохраняются лишь в журналах сервера. Это может вызвать затруднения при просмотре и сопоставления планов, обнаруженных в логах, с метриками, сохраненными с помощью pg_stat_statements.
SQL Monitor упрощает эти сложности, читая планы запросов из журнала, сопоставляя их со статисткой во времени, собранной из pg_stat_statements, и предоставляя визуальный просмотрщик плана запроса. С помощью этого просмотрщика визуализируется статистика времени исполнения запроса для всего плана выполнения и для каждого отдельного узла плана, чтобы увидеть связанные с ним дополнительные детали:
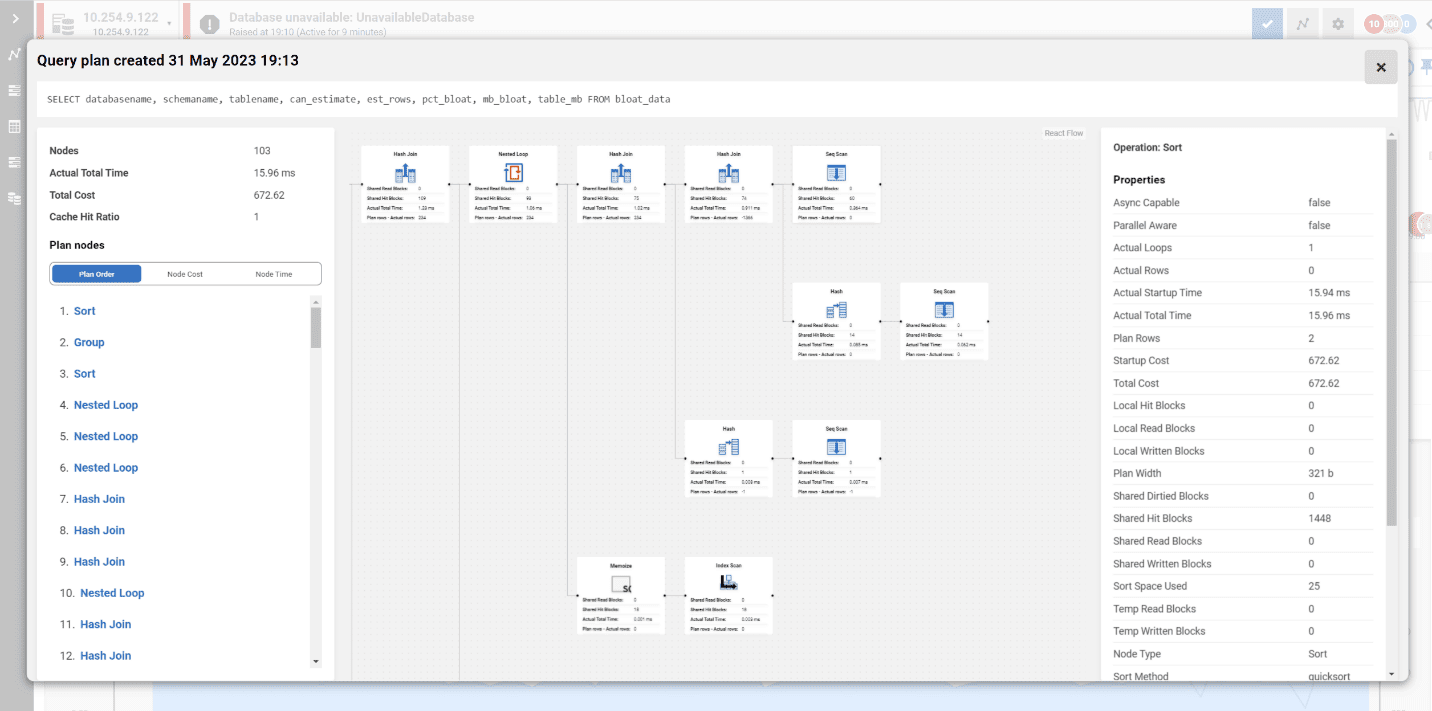
Детали плана выполнения PostgreSQL отличаются от того, что вы обычно видите в других базах данных, но концепции те же самые, и визуализация плана в SQL Monitor может помочь вам понять проблемные части вашего запроса. Для каждого узла визуальный план показывает число блоков (страниц), которые были считаны из кэша (Shared Hit Blocks) или с диска (Shared Read Blocks). Поскольку каждая страница имеет размер 8Кб, чем больше страниц читает запрос, тем медленнее общая производительность.
Кроме того, во многом подобно SQL Server, устаревшая статистика часто может привести планировщик запросов к выбору плохих планов запроса. Поэтому SQL Monitor подсвечивает разницу между "планируемыми строками" (planned rows) и "фактическими строками" (actual rows), которые возвращаются на каждом шаге. Когда планировщик существенно недооценивает или переоценивает число строк, которые должны удовлетворять предикату запроса (условие поиска), то обычно страдает производительность. Если у нас есть простой способ увидеть эти расхождения в плане запроса, мы сможем лучше выявить те запросы или процессы, которые нуждаются в улучшении.
Ресурсы сервера ограничены. Только понимание того, как используются ресурсы при увеличении нагрузки на приложение, позволяет администратору БД принимать осознанные решения проблем узких мест использования ресурсов. Следует ли нам, например, увеличить доступную память или ресурсы процессора, или изменить конфигурацию сервера для лучшего использования имеющихся ресурсов?
PostgreSQL имеет сильную корреляцию между использованием памяти и числом активных подключений пользователей. В отличие от других баз данных, которые используют множество потоков или встроенный пул подключений, каждое подключение к PostgreSQL обрабатывается отдельным процессом. Кроме того, память, которую подключение может использовать для удовлетворения потребностей запроса является произведением значением настройки work_mem (количество RAM, которое может быть выделено запросу до создания файла на диске) на сложность запроса (число операций в плане выполнения запроса). Следовательно, по мере роста числа параллельных подключений важно иметь представление о том, как взаимодействуют подключения, память и нагрузка сервера.
SQL Monitor может обнаружить эту тенденцию парой способов.
Во-первых, для каждого экземпляра отображаются ключевые метрики сервера и времени исполнения в виде множества полезных диаграмм во временных границах, которые составляют полный временной диапазон графика.
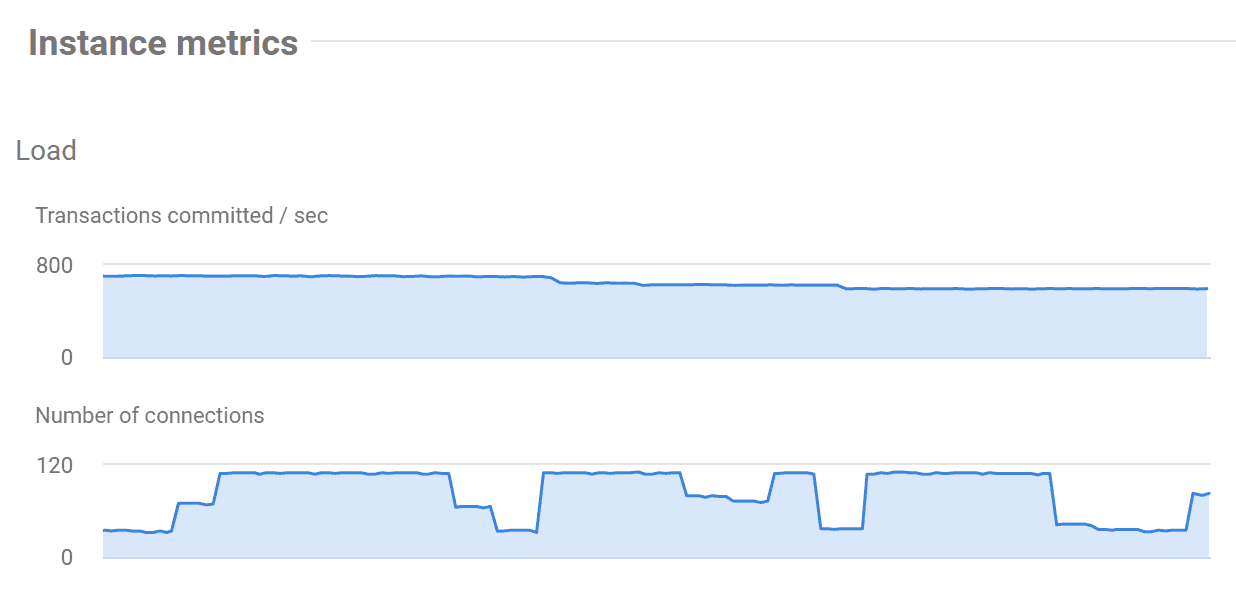
Здесь мы получаем быстрое представление о поведении подключений по времени. По умолчанию PostgreSQL сконфигурирован на 100 подключений. Если число подключений совпадает или близко к максимальному значению настройки, или оно приходится на периоды медленных запросов, это указывает, что сервер мог быть ограничен в ресурсах для текущей рабочей нагрузки.
Увеличение числа доступных подключений может решить проблему роста производительности, или, возможно, сервер не имеет достаточно свободных ресурсов ЦП или памяти для выполнения текущей нагрузки по запросам. Встроенное в SQL Monitor предупреждение о проценте используемых подключений (Percentage of connections used) предупредит вас, если число подключений превысит процентное пороговое значение max_connections для определенного периода.
Если известные проблемы производительности коррелируют по времен с высоким числом подключений, это также служит показателем того, что тяжелая нагрузка могла быть вызвана тем, что сервер поставил запросы в очередь в то время, когда требовалось больше ресурсов. В сочетании с другими данными типа Cache Hit Ratio (коэффициент попадания в кэш), мы можем начать проверку потребности сервера в увеличении физических ресурсов на основе текущей нагрузки и характеристик запросов.
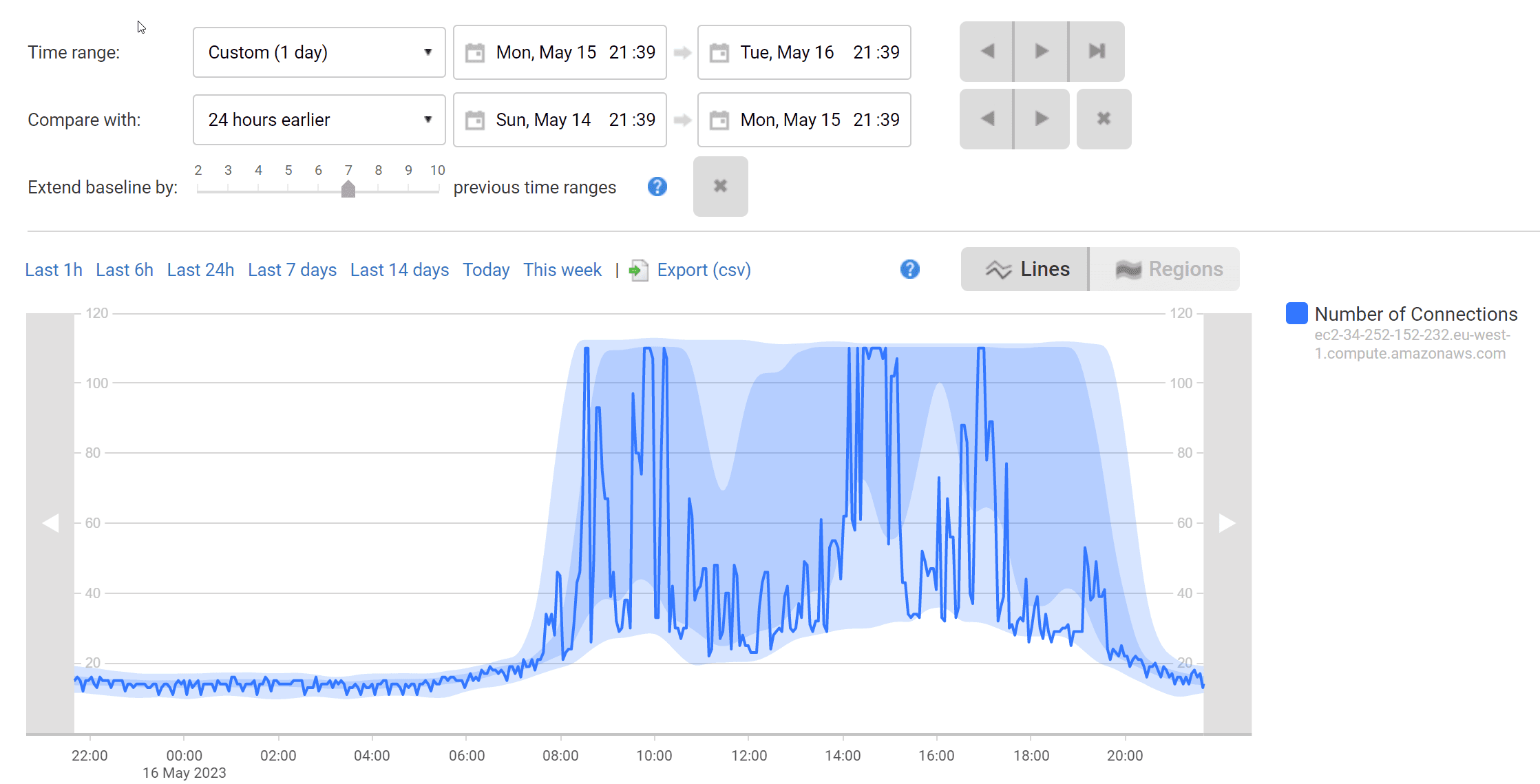
Еще лучше иметь неоценимую возможность легко просматривать историю изменения базовой линии во время процесса исследования. SQL Monitor предоставляет легкий доступ к данным базовой линии, установленной на выбранное вами временное окно. Ниже мы можем оценить, является ли текущая нагрузка подключений типичной для приложения во время этого периода времени дня.
В некоторых базах данных, подобных SQL Server, cache hit ratio не помогает идентифицировать ограниченные ресурсы сервера, как и другие метрики. Однако в PostgreSQL использование кэша напрямую связано с количеством доступной для хранения страниц данных памяти и использованием этих страниц во времени. PostgreSQL в настоящее время не имеет статистики, подобной Page Life Expectancy (ожидаемое время жизни страницы) в SQL Server.
Пытаясь сберечь финансовые ресурсы, администраторы БД зачастую вынуждены выжимать максимум возможной производительности из ограниченных ресурсов сервера, временами не вполне понимая, насколько плохо это может сказаться на производительности запросов. Количество памяти, которое PostgreSQL может использовать для кэширования страниц данных, фиксируется конфигурационным параметром shared_buffers и должна быть частью общей памяти, доступной серверу. Если это зарезервированное пространство недостаточно велико, чтобы содержать все активно запрашиваемые данные, многие страницы должны будут считываться с диска для выполнения запроса. Значением по умолчанию для shared_buffers является 128Мб, чего категорически недостаточно для современной производственной нагрузки.
База данных, которая возрастает со временем, особенно количество "активных" данных, может просто замедлить работу, поскольку ей недостает ресурсов памяти, чтобы соответствовать нагрузке запросов. Это становится очевидным при исследовании раздела Efficiency обзора сервера в SQL Monitor.

Каждый раз, когда коэффициент попаданий в кэш ниже 90 % или постоянно падает, что связано с высоким использованием и плохой производительностью, это является показателем того, что сервер не имеет достаточно ресурсов, чтобы хранить активные страницы в памяти. Увеличение доступной памяти или улучшение неэффективных запросов часто является лучшим способом для смягчения проблем с ограниченной памятью.
PostgreSQL использует уникальную реализацию изоляции транзакций с помощью Многоверсионного управления параллелизмом (MVCC). Вместо сохранения модифицированных строк в отдельном файле журнала или во временной таблице, PostgreSQL записывает новые версии строк (называемых кортежами - Tuples) в той же самой таблице с использованием ИД транзакции (XID) для пометки того, какую версию строки должны видеть выполняющиеся в данный момент транзакции. Когда все транзакции завершают работу, которым требовалась версия строки, она считается мертвым кортежем (dead tuple) и может быть удалена. Эта очистка выполняется процессом, который называется vacuum, он освобождает место для новых данных и гарантирует правильное обслуживание ИД последующих транзакций.
Вакуумирование является настолько важной задачей для правильного функционирования базы данных PostgreSQL, что процесс с именем autovacuum выполняется автоматически на всех серверах. Хотя он может быть выключен в конфигурации, делать так весьма неосмотрительно, по крайней мере, без достаточного опыта и планирования его последующего включения. Если эти мертвые кортежи не удалять, то общая производительность базы данных PostgreSQL будет страдать по многим причинам. Например, для возвращения требуемого множества "живых" строк данных PostgreSQL придется читать больше страниц с диска, что увеличит дисковый ввод/вывод. Подобным образом упадет эффективность индексов, т.к. PostgreSQL должен переходить по указателям на большее число страниц для получения тех же самых данных. Все вместе, в конце концов, приведет к ненормальной производительности базы данных при неправильном обслуживании вакуумизации. Прочитайте статью PostgreSQL (auto) vacuum - уже не тайна с подробным описанием работы MVCC, роли автоматического вакуумирования и важных параметрах, которые управляют его поведением.
При надлежащем обслуживании легко выявить нездоровую производительность вакуумирования и те области, где может потребоваться изменение конфигурации. Плохо обслуживаемые базы данных из-за проблем с вакуумированием обычно проявляются по крайней мере в трех областях: раздувание таблиц, устаревшая статистика таблиц и увеличивающийся риск исчерпания ИД транзакций.
Проще всего обнаружить и разобраться с раздуванием таблиц.
Всякий, кто обслуживал реляционную базу данных, знаком с потенциальными причинами раздувания, условием, когда место на диске непропорционально количеству данных в таблице или базе данных. Причины, по которым происходит раздувание таблицы, разнятся для разных движков баз данных. Например, в SQL Server некорректная настройка бэкапов журнала может легко привести к тому, что база данных займет больше дискового пространства, чем это необходимо, что потребует в будущем больше работы по обслуживанию.
В исправном и правильно настроенном экземпляре PostgreSQL процесс автоматического вакуумирования легко обслуживает базу данных и сохраняет раздувание таблиц на уровне. Однако если ресурсы сервера неадекватны или нетрадиционные шаблоны использования вызывают нарушение процесса автоматического вакуумирования, вам нужно сразу знать, что это произошло.
Один из способов, который может выявить раздувание таблицы, — это отношение живых кортежей к мертвым кортежам. Помните, что мертвый кортеж относится к строке на диске, которая больше не будет использоваться другой транзакцией; это старые данные, которые требуется почистить, чтобы новые строки могли использовать это пространство. Если число мертвых кортежей продолжает расти, это значит, что автоматическое вакуумирование не выполняет свою работу надлежащим образом.
SQL Monitor имеет специфичное для PostgreSQL представление на главной странице Server Overview, которое подсвечивает установки вакуумирования и метрики размера таблицы. Каждая таблица, превышающая 50Мб, будет представлена в этой области текущей статистикой использования.
Как можно увидеть в примере ниже, таблица заказов содержит почти 3,5Гб мертвых кортежей, более 8,5% от общего размера таблицы. В течение 24-часового отображаемого периода не было уменьшения общего пространства, используемого мертвыми кортежами, что говорит о том, что в это время вакуумирования не происходило. Это может быть проблемой настроек или долго выполняющейся транзакции, которая не давала возможности удалить мертвые кортежи.
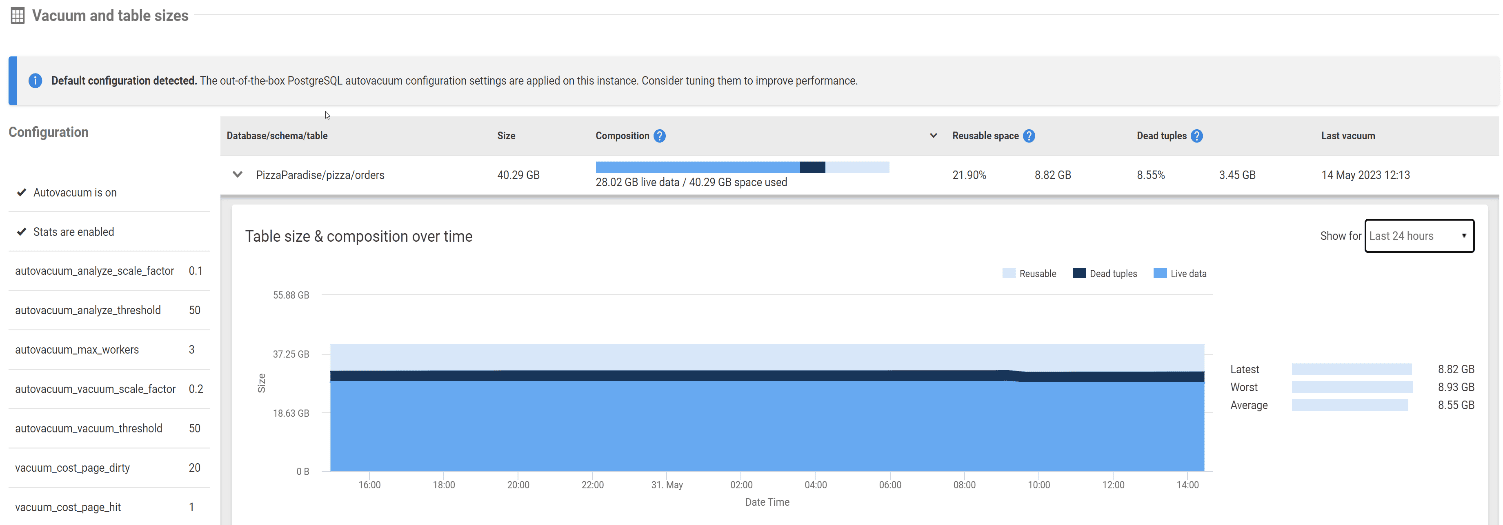
Мы можем увидеть в столбце Last vacuum, что фактически эта таблица не очищалась около недели. Скриншот был сделан 31 мая 2023, в то время как последнее вакуумирование выполнялось 14 мая 2023. Поскольку так много места в этой таблице занято мертвыми кортежами, она является очевидным кандидатом для дальнейшего исследования.
Если мы уменьшим масштаб и найдем более крупный тренд, станет ясно, что мертвые кортежи периодически удалялись, но часто с недельной или более периодичностью. Наиболее вероятная причина такого поведения заключается в том, что автоматическое вакуумирование запускалось на основе изменения процентного отношения строк, подобно тому, как триггеры обновляют статистику таблиц в SQL Server. По умолчанию этот значение составляет 20% от общего числа строк в таблице. На таблице с 10000 строками автоматическое вакуумирование будет срабатывать примерно после модификации 2000 строк. Однако по мере того, как таблица становится больше, все больше мертвых кортежей будет скапливаться до освобождения пространства для новых данных.
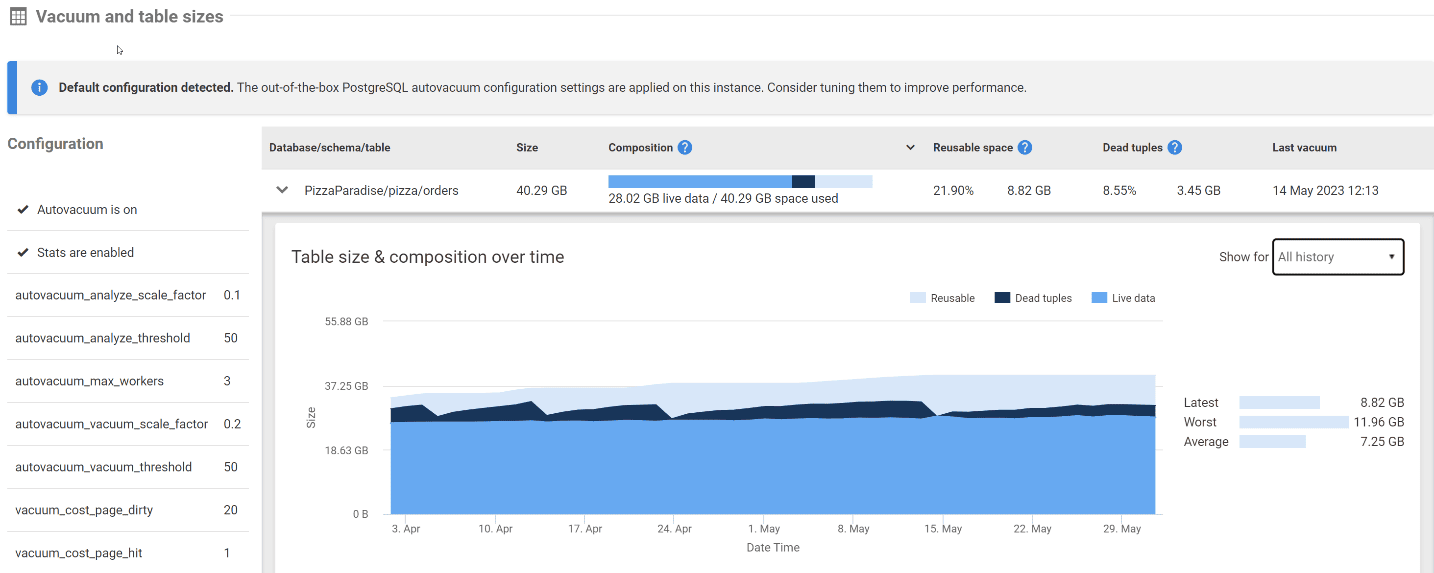
В этой ситуации, возможно, стоит понизить порог автоматического вакуумирования на более низкий процент, чтобы такие большие таблицы очищались более часто. Это держит под контролем раздувание таблицы и гарантирует, что использование дискового пространства таблицы не будет расти сверх необходимого между процессами вакуумирования.
Другим важным аспектом применения MVCC в PostgreSQL является то, что идентификаторы транзакций, которые определяют видимость строки ограничены примерно 2,1 миллиардами (2^31) целых значений. Всякий раз, когда выполняется процесс очистки, либо вручную, либо автоматически, PostgreSQL идентифицирует ИД транзакций, которые могут быть "заморожены", по сути, возвращая идентификаторы транзакций в пул с тем, чтобы доступного пространства значений ИД было достаточно для будущих транзакций.
Если длительные транзакции или какие-либо другие проблемы мешают процессу вакуумирования нормально управлять пространством ИД транзакций, экземпляр PostgreSQL в конечном итоге исчерпает доступные идентификаторы и будет препятствовать модификации любых данных до тех пор, пока пространство ИД не будет соответствующим образом очищено. Это называется зацикливанием или исчерпанием идентификаторов транзакций.
Хотя весьма необычно для большинства инсталляций PostgreSQL испытывать исчерпание ИД транзакций, существенно, чтобы ваше решение по мониторингу отслеживало текущие уровни и обеспечивало надежное оповещение, чтобы позволить упреждающее обслуживание пространства идентификатора транзакции. Без надлежащего отслеживания и оповещения исчерпание ИД транзакций может вывести базу данных PostgreSQL в офлайн, результат, который ни один администратор баз данных не хочет испытать на себе без предупреждения. Используя решение мониторинга, которое отслеживает и оповещает о длительных транзакциях и использовании ИД транзакций, администраторы БД могут решать загодя любые проблемы, которые могут возникнуть в базе данных PostgreSQL.
SQL Monitor имеет встроенную метрику, которая позволяет визуализировать текущий процентный уровень использования ИД транзакций в базе данных. Помимо этого, по умолчанию SQL Monitor будет посылать предупреждение всякий раз, когда использование ИД транзакций достигает указанного порогового значения. Знать заранее, что что-то мешает нормальному обслуживанию пространства значений ИД транзакций, помогает администраторам БД быстро решать возникающие проблемы.
PostgreSQL может справляться с огромными рабочими нагрузками всех форм и размеров. Знание эффективного мониторинга PostgreSQL может столкнуться с трудностями понимания особенно у тех пользователей, которые имеют глубокие корни в других базах данных, например, SQL Server. Инструменты типа SQL Monitor помогают автоматизировать сбор данных, высветить ключевые проблемные области и эффективно управлять оповещениями для большинства важных проблем.
В этой статье описывается лишь малая часть метрик, которая требует особенного пристального внимания при мониторинге PostgreSQL. Если вы заранее знаете о необычных шаблонах поведения этих метрик или комбинации метрик, вы сможете действовать с опережением, пока "ненормальный тренд" не стал проблемой, которая влияет на производительность приложения. По мере того, как вы и ваша команда работаете над реализацией эффективного плана мониторинга и оптимизации производительности PostgreSQL, внимание к этим показателям поможет вам достичь поставленных целей по времени безотказной работы и производительности.
Ссылки по теме
1. Автоматическая корректировка планов в SQL Server
2. Анатомия плана запроса в PostgreSQL
3. PostgreSQL для администраторов SQL Server: первые четыре настройки для проверки
4. Полезные команды/запросы PostgreSQL
5. Введение в управление параллелизмом в PostgreSQL
Для некоторых администраторов БД, которые имеют большой опыт работы на другой платформе, как-то SQL Server, понимание мониторинга базы данных для достижения пиковой производительности может поначалу показаться сложным. Из-за природы продукта с открытым кодом проблема проактивного мониторинга пока не решена в экосистеме PostgreSQL. PostgreSQL имеет много метрик, которые могут обеспечить понимание текущего состояния базы данных или сервера, но автоматизированный согласованный мониторинг не встроен в ядро продукта с открытым кодом.
Чтобы получить максимум от платформы, важно иметь инструменты, которые могут легко получить эти метрики и помочь вам осмыслить цифры в данный момент и с течением времени. SQL Monitor собирает широкий набор тех метрик для PostgreSQL, которые предназначены, чтобы помочь вам идентифицировать и диагностировать все общие причины падения производительности или проблемы обслуживания в базах данных PostgreSQL. В этой статье мы обсудим шесть из этих метрик PostgreSQL, которые следует постоянно отслеживать на уровне сервера и базы данных, чтобы обеспечить гладкую работу и показать вам, как SQL Monitor готов помочь вам в этом.
Понимание производительности запроса
Нет ничего хуже, чем иметь медленно выполняющийся запрос в приложении и не иметь возможности понять почему. Некоторые базы данных имеют функции, которые помогают вам идентифицировать, почему производительность запроса изменилась с течением времени для отдельных запросов (например, функционал хранилища запросов, Query Store, в SQL Server).
PostgreSQL, с другой стороны, пока не обладает встроенными процессами или компонентами, которые автоматически делали бы это за вас. Хотя существует много необходимых метрик, и они поддерживаются на всех версиях PostgreSQL, мониторинг медленно выполняющихся запросов по-прежнему возлагается на конечного пользователя.
При правильном конфигурировании все поддерживаемые версии PostgreSQL собирают статистику о выполнении каждого запроса, если расширение pg_stat_statements установлено и доступно для, по крайней мере, одной базы данных в кластере. Сейчас PostgreSQL сохраняет только накопительные общие значения метрик для каждого запроса, и вы найдете много инструментов онлайн и тестовых запросов, которые покажут вам средние значения для конкретного запроса. Однако пока вы не захватываете и не сохраняете "снимки" этих данных, у вас не будет способа идентифицировать, какой запрос влияет на производительность сервера прямо сейчас, или в какой-то момент времени в прошлом, или понять, деградировала ли производительность конкретного запроса внезапно или постепенно с течением времени.
Вот где инструмент типа SQL Monitor может быть особенно полезен, поскольку он будет автоматически отслеживать статистику производительности этих запросов, значительно облегчая обнаружение проблем. Предполагая, что pg_stat_statements установлено, SQL Monitor будет периодически извлекать данные и сохранять снимки статистики. Он выводит эти данные в разделе Top Queries (топовые запросы) обзора сервера (Server Overview), что делает много проще как идентификацию наиболее дорогих запросов, которые выполняются в период падения производительности, так и понять тенденцию в производительности запроса в течение времени.
Top Queries
Раздел Top Queries позволяет вам быстро фильтровать наиболее дорогие запросы на основе определенных характеристик. Эта область фильтруется по тому же самому диапазону времени, что и страница с общими метриками сервера, помогая пользователям сфокусировать усилия на исследовании.
В пределах этого диапазона времени вы можете сортировать топовые запросы на основе средних или общих метрических значений по любым отслеживаемым метрикам. Например, если производительность сервера упала за последний час, часто полезно посмотреть, какие запросы выполнялись чаще или имели наибольшее среднее время выполнения. Панель подробной информации, открываемая для любого запроса в списке, покажет полный текст запроса и историю среднего числа выполнений и их продолжительность во времени.
Получение и визуализация планов запросов и статистики
Идентифицировав дорогой запрос или тот, который кажется выполняется ненормально, план запроса часто поможет нам понять, почему это происходит. Однако упреждающий захват планов запросов не происходит автоматически в PostgreSQL. Напротив, он требует расширения auto_explain, и планы запросов сохраняются лишь в журналах сервера. Это может вызвать затруднения при просмотре и сопоставления планов, обнаруженных в логах, с метриками, сохраненными с помощью pg_stat_statements.
SQL Monitor упрощает эти сложности, читая планы запросов из журнала, сопоставляя их со статисткой во времени, собранной из pg_stat_statements, и предоставляя визуальный просмотрщик плана запроса. С помощью этого просмотрщика визуализируется статистика времени исполнения запроса для всего плана выполнения и для каждого отдельного узла плана, чтобы увидеть связанные с ним дополнительные детали:
Детали плана выполнения PostgreSQL отличаются от того, что вы обычно видите в других базах данных, но концепции те же самые, и визуализация плана в SQL Monitor может помочь вам понять проблемные части вашего запроса. Для каждого узла визуальный план показывает число блоков (страниц), которые были считаны из кэша (Shared Hit Blocks) или с диска (Shared Read Blocks). Поскольку каждая страница имеет размер 8Кб, чем больше страниц читает запрос, тем медленнее общая производительность.
Кроме того, во многом подобно SQL Server, устаревшая статистика часто может привести планировщик запросов к выбору плохих планов запроса. Поэтому SQL Monitor подсвечивает разницу между "планируемыми строками" (planned rows) и "фактическими строками" (actual rows), которые возвращаются на каждом шаге. Когда планировщик существенно недооценивает или переоценивает число строк, которые должны удовлетворять предикату запроса (условие поиска), то обычно страдает производительность. Если у нас есть простой способ увидеть эти расхождения в плане запроса, мы сможем лучше выявить те запросы или процессы, которые нуждаются в улучшении.
Мониторинг использования ресурсов сервера
Ресурсы сервера ограничены. Только понимание того, как используются ресурсы при увеличении нагрузки на приложение, позволяет администратору БД принимать осознанные решения проблем узких мест использования ресурсов. Следует ли нам, например, увеличить доступную память или ресурсы процессора, или изменить конфигурацию сервера для лучшего использования имеющихся ресурсов?
PostgreSQL имеет сильную корреляцию между использованием памяти и числом активных подключений пользователей. В отличие от других баз данных, которые используют множество потоков или встроенный пул подключений, каждое подключение к PostgreSQL обрабатывается отдельным процессом. Кроме того, память, которую подключение может использовать для удовлетворения потребностей запроса является произведением значением настройки work_mem (количество RAM, которое может быть выделено запросу до создания файла на диске) на сложность запроса (число операций в плане выполнения запроса). Следовательно, по мере роста числа параллельных подключений важно иметь представление о том, как взаимодействуют подключения, память и нагрузка сервера.
SQL Monitor может обнаружить эту тенденцию парой способов.
Число подключений
Во-первых, для каждого экземпляра отображаются ключевые метрики сервера и времени исполнения в виде множества полезных диаграмм во временных границах, которые составляют полный временной диапазон графика.
Здесь мы получаем быстрое представление о поведении подключений по времени. По умолчанию PostgreSQL сконфигурирован на 100 подключений. Если число подключений совпадает или близко к максимальному значению настройки, или оно приходится на периоды медленных запросов, это указывает, что сервер мог быть ограничен в ресурсах для текущей рабочей нагрузки.
Увеличение числа доступных подключений может решить проблему роста производительности, или, возможно, сервер не имеет достаточно свободных ресурсов ЦП или памяти для выполнения текущей нагрузки по запросам. Встроенное в SQL Monitor предупреждение о проценте используемых подключений (Percentage of connections used) предупредит вас, если число подключений превысит процентное пороговое значение max_connections для определенного периода.
Если известные проблемы производительности коррелируют по времен с высоким числом подключений, это также служит показателем того, что тяжелая нагрузка могла быть вызвана тем, что сервер поставил запросы в очередь в то время, когда требовалось больше ресурсов. В сочетании с другими данными типа Cache Hit Ratio (коэффициент попадания в кэш), мы можем начать проверку потребности сервера в увеличении физических ресурсов на основе текущей нагрузки и характеристик запросов.
Еще лучше иметь неоценимую возможность легко просматривать историю изменения базовой линии во время процесса исследования. SQL Monitor предоставляет легкий доступ к данным базовой линии, установленной на выбранное вами временное окно. Ниже мы можем оценить, является ли текущая нагрузка подключений типичной для приложения во время этого периода времени дня.
Cache Hit Ratio
В некоторых базах данных, подобных SQL Server, cache hit ratio не помогает идентифицировать ограниченные ресурсы сервера, как и другие метрики. Однако в PostgreSQL использование кэша напрямую связано с количеством доступной для хранения страниц данных памяти и использованием этих страниц во времени. PostgreSQL в настоящее время не имеет статистики, подобной Page Life Expectancy (ожидаемое время жизни страницы) в SQL Server.
Пытаясь сберечь финансовые ресурсы, администраторы БД зачастую вынуждены выжимать максимум возможной производительности из ограниченных ресурсов сервера, временами не вполне понимая, насколько плохо это может сказаться на производительности запросов. Количество памяти, которое PostgreSQL может использовать для кэширования страниц данных, фиксируется конфигурационным параметром shared_buffers и должна быть частью общей памяти, доступной серверу. Если это зарезервированное пространство недостаточно велико, чтобы содержать все активно запрашиваемые данные, многие страницы должны будут считываться с диска для выполнения запроса. Значением по умолчанию для shared_buffers является 128Мб, чего категорически недостаточно для современной производственной нагрузки.
База данных, которая возрастает со временем, особенно количество "активных" данных, может просто замедлить работу, поскольку ей недостает ресурсов памяти, чтобы соответствовать нагрузке запросов. Это становится очевидным при исследовании раздела Efficiency обзора сервера в SQL Monitor.
Каждый раз, когда коэффициент попаданий в кэш ниже 90 % или постоянно падает, что связано с высоким использованием и плохой производительностью, это является показателем того, что сервер не имеет достаточно ресурсов, чтобы хранить активные страницы в памяти. Увеличение доступной памяти или улучшение неэффективных запросов часто является лучшим способом для смягчения проблем с ограниченной памятью.
Обслуживание PostgreSQL с помощью Vacuum
PostgreSQL использует уникальную реализацию изоляции транзакций с помощью Многоверсионного управления параллелизмом (MVCC). Вместо сохранения модифицированных строк в отдельном файле журнала или во временной таблице, PostgreSQL записывает новые версии строк (называемых кортежами - Tuples) в той же самой таблице с использованием ИД транзакции (XID) для пометки того, какую версию строки должны видеть выполняющиеся в данный момент транзакции. Когда все транзакции завершают работу, которым требовалась версия строки, она считается мертвым кортежем (dead tuple) и может быть удалена. Эта очистка выполняется процессом, который называется vacuum, он освобождает место для новых данных и гарантирует правильное обслуживание ИД последующих транзакций.
Вакуумирование является настолько важной задачей для правильного функционирования базы данных PostgreSQL, что процесс с именем autovacuum выполняется автоматически на всех серверах. Хотя он может быть выключен в конфигурации, делать так весьма неосмотрительно, по крайней мере, без достаточного опыта и планирования его последующего включения. Если эти мертвые кортежи не удалять, то общая производительность базы данных PostgreSQL будет страдать по многим причинам. Например, для возвращения требуемого множества "живых" строк данных PostgreSQL придется читать больше страниц с диска, что увеличит дисковый ввод/вывод. Подобным образом упадет эффективность индексов, т.к. PostgreSQL должен переходить по указателям на большее число страниц для получения тех же самых данных. Все вместе, в конце концов, приведет к ненормальной производительности базы данных при неправильном обслуживании вакуумизации. Прочитайте статью PostgreSQL (auto) vacuum - уже не тайна с подробным описанием работы MVCC, роли автоматического вакуумирования и важных параметрах, которые управляют его поведением.
При надлежащем обслуживании легко выявить нездоровую производительность вакуумирования и те области, где может потребоваться изменение конфигурации. Плохо обслуживаемые базы данных из-за проблем с вакуумированием обычно проявляются по крайней мере в трех областях: раздувание таблиц, устаревшая статистика таблиц и увеличивающийся риск исчерпания ИД транзакций.
Проще всего обнаружить и разобраться с раздуванием таблиц.
Раздувание таблиц
Всякий, кто обслуживал реляционную базу данных, знаком с потенциальными причинами раздувания, условием, когда место на диске непропорционально количеству данных в таблице или базе данных. Причины, по которым происходит раздувание таблицы, разнятся для разных движков баз данных. Например, в SQL Server некорректная настройка бэкапов журнала может легко привести к тому, что база данных займет больше дискового пространства, чем это необходимо, что потребует в будущем больше работы по обслуживанию.
В исправном и правильно настроенном экземпляре PostgreSQL процесс автоматического вакуумирования легко обслуживает базу данных и сохраняет раздувание таблиц на уровне. Однако если ресурсы сервера неадекватны или нетрадиционные шаблоны использования вызывают нарушение процесса автоматического вакуумирования, вам нужно сразу знать, что это произошло.
Один из способов, который может выявить раздувание таблицы, — это отношение живых кортежей к мертвым кортежам. Помните, что мертвый кортеж относится к строке на диске, которая больше не будет использоваться другой транзакцией; это старые данные, которые требуется почистить, чтобы новые строки могли использовать это пространство. Если число мертвых кортежей продолжает расти, это значит, что автоматическое вакуумирование не выполняет свою работу надлежащим образом.
SQL Monitor имеет специфичное для PostgreSQL представление на главной странице Server Overview, которое подсвечивает установки вакуумирования и метрики размера таблицы. Каждая таблица, превышающая 50Мб, будет представлена в этой области текущей статистикой использования.
Как можно увидеть в примере ниже, таблица заказов содержит почти 3,5Гб мертвых кортежей, более 8,5% от общего размера таблицы. В течение 24-часового отображаемого периода не было уменьшения общего пространства, используемого мертвыми кортежами, что говорит о том, что в это время вакуумирования не происходило. Это может быть проблемой настроек или долго выполняющейся транзакции, которая не давала возможности удалить мертвые кортежи.
Мы можем увидеть в столбце Last vacuum, что фактически эта таблица не очищалась около недели. Скриншот был сделан 31 мая 2023, в то время как последнее вакуумирование выполнялось 14 мая 2023. Поскольку так много места в этой таблице занято мертвыми кортежами, она является очевидным кандидатом для дальнейшего исследования.
Если мы уменьшим масштаб и найдем более крупный тренд, станет ясно, что мертвые кортежи периодически удалялись, но часто с недельной или более периодичностью. Наиболее вероятная причина такого поведения заключается в том, что автоматическое вакуумирование запускалось на основе изменения процентного отношения строк, подобно тому, как триггеры обновляют статистику таблиц в SQL Server. По умолчанию этот значение составляет 20% от общего числа строк в таблице. На таблице с 10000 строками автоматическое вакуумирование будет срабатывать примерно после модификации 2000 строк. Однако по мере того, как таблица становится больше, все больше мертвых кортежей будет скапливаться до освобождения пространства для новых данных.
В этой ситуации, возможно, стоит понизить порог автоматического вакуумирования на более низкий процент, чтобы такие большие таблицы очищались более часто. Это держит под контролем раздувание таблицы и гарантирует, что использование дискового пространства таблицы не будет расти сверх необходимого между процессами вакуумирования.
Исчерпание ИД транзакции
Другим важным аспектом применения MVCC в PostgreSQL является то, что идентификаторы транзакций, которые определяют видимость строки ограничены примерно 2,1 миллиардами (2^31) целых значений. Всякий раз, когда выполняется процесс очистки, либо вручную, либо автоматически, PostgreSQL идентифицирует ИД транзакций, которые могут быть "заморожены", по сути, возвращая идентификаторы транзакций в пул с тем, чтобы доступного пространства значений ИД было достаточно для будущих транзакций.
Если длительные транзакции или какие-либо другие проблемы мешают процессу вакуумирования нормально управлять пространством ИД транзакций, экземпляр PostgreSQL в конечном итоге исчерпает доступные идентификаторы и будет препятствовать модификации любых данных до тех пор, пока пространство ИД не будет соответствующим образом очищено. Это называется зацикливанием или исчерпанием идентификаторов транзакций.
Хотя весьма необычно для большинства инсталляций PostgreSQL испытывать исчерпание ИД транзакций, существенно, чтобы ваше решение по мониторингу отслеживало текущие уровни и обеспечивало надежное оповещение, чтобы позволить упреждающее обслуживание пространства идентификатора транзакции. Без надлежащего отслеживания и оповещения исчерпание ИД транзакций может вывести базу данных PostgreSQL в офлайн, результат, который ни один администратор баз данных не хочет испытать на себе без предупреждения. Используя решение мониторинга, которое отслеживает и оповещает о длительных транзакциях и использовании ИД транзакций, администраторы БД могут решать загодя любые проблемы, которые могут возникнуть в базе данных PostgreSQL.
SQL Monitor имеет встроенную метрику, которая позволяет визуализировать текущий процентный уровень использования ИД транзакций в базе данных. Помимо этого, по умолчанию SQL Monitor будет посылать предупреждение всякий раз, когда использование ИД транзакций достигает указанного порогового значения. Знать заранее, что что-то мешает нормальному обслуживанию пространства значений ИД транзакций, помогает администраторам БД быстро решать возникающие проблемы.
Заключение
PostgreSQL может справляться с огромными рабочими нагрузками всех форм и размеров. Знание эффективного мониторинга PostgreSQL может столкнуться с трудностями понимания особенно у тех пользователей, которые имеют глубокие корни в других базах данных, например, SQL Server. Инструменты типа SQL Monitor помогают автоматизировать сбор данных, высветить ключевые проблемные области и эффективно управлять оповещениями для большинства важных проблем.
В этой статье описывается лишь малая часть метрик, которая требует особенного пристального внимания при мониторинге PostgreSQL. Если вы заранее знаете о необычных шаблонах поведения этих метрик или комбинации метрик, вы сможете действовать с опережением, пока "ненормальный тренд" не стал проблемой, которая влияет на производительность приложения. По мере того, как вы и ваша команда работаете над реализацией эффективного плана мониторинга и оптимизации производительности PostgreSQL, внимание к этим показателям поможет вам достичь поставленных целей по времени безотказной работы и производительности.
Ссылки по теме
1. Автоматическая корректировка планов в SQL Server
2. Анатомия плана запроса в PostgreSQL
3. PostgreSQL для администраторов SQL Server: первые четыре настройки для проверки
4. Полезные команды/запросы PostgreSQL
5. Введение в управление параллелизмом в PostgreSQL
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой