
Построение индексов SQL Server в возрастающем и убывающем порядке
Пересказ статьи Greg Robidoux. Building SQL Server Indexes in Ascending vs Descending Order
Проблема
При построении индексов часто используется вариант по умолчанию, а именно, индекс строится в возрастающем порядке. Это обычно является наиболее подходящим вариантом создания индекса, поскольку наиболее старые данные или наименьшие значения оказываются наверху, а новые или наибольшие внизу. Хотя поиск по индексу работает прекрасно на таких индексах, но думали ли вы о необходимости всегда получать сначала наиболее свежие данные и о том, что вы можете создать индекс в убывающем порядке, при котором наиболее свежие данные всегда находятся наверху индекса?
Давайте посмотрим, как это работает, и есть ли преимущества в построении индекса в убывающем порядке по сравнению с индексом по умолчанию.
При создании индекса имеется опция для задания порядка следования значений в индексе. Это может быть сделано просто использованием ключевого слова ASC или DESC при создании индекса, как показано ниже. Все последующие примеры используют демонстрационную базу данных AdventureWorks.
Вот простой код, который демонстрирует создание индекса в убывающем или возрастающем порядке.
Создание индекса в убывающем порядке:
Создание индекса в возрастающем порядке:
Давайте напишем пару запросов и посмотрим их планы, чтобы оценить разницу.
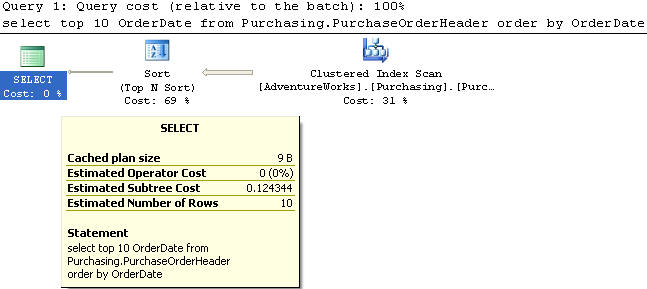
В этом примере мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в возрастающем порядке. Индекса на столбце OrderDate нет.
Этот запрос выполняет сканирование кластеризованного индекса и имеет стоимость 0,124344.
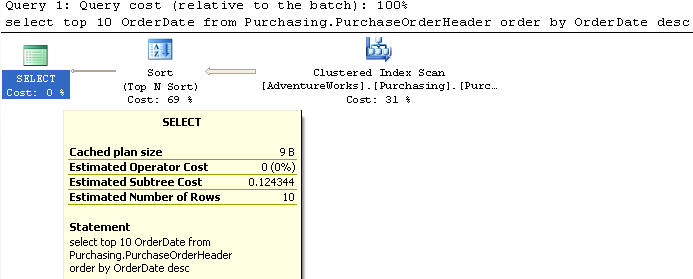
В этом примере мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в убывающем порядке. Индекса на столбце OrderDate нет.
Этот запрос выполняет сканирование кластеризованного индекса и имеет стоимость 0,124344, как и в предыдущем примере.
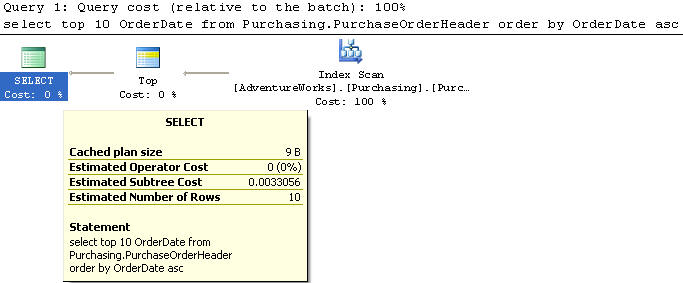
В этом примере мы создаем индекс на OrderDate в возрастающем порядке.
В этом примере мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в возрастающем порядке.
Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033056, что много лучше предыдущего значения 0,124344.
Таким образом, мы наблюдаем, что добавление индекса делает запрос значительно быстрее.
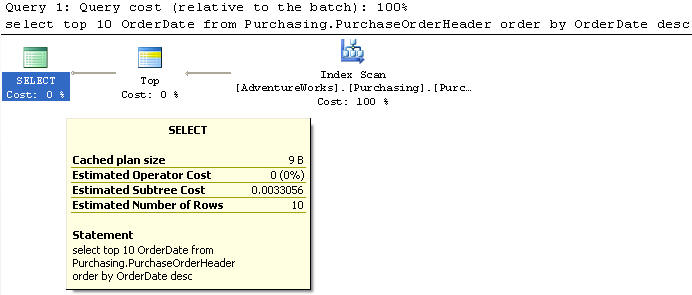
В этом примере мы снова будем использовать новый индекс на OrderDate в возрастающем порядке.
Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в убывающем порядке.
Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033056, как и в примере 3.
Обратите внимание, что хотя индекс был создан по возрастанию, получение данных в убывающем порядке выполняется так же быстро, как и в возрастающем.
Хотя мы уже видели, что выборка данных в убывающем порядке с индексом по возрастанию не имеет отличий, давайте все же сделаем проверку для уверенности.
В этом примере мы создали индекс на OrderDate в убывающем порядке. Мы удалим индекс и пересоздадим его.
Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в возрастающем порядке.
Этот запрос выполняет сканирование нового индекса и имеет стоимость 0,0033056, что совпадает с предыдущим примером; так что нет никаких отличий.
Следует еще проверить случай, когда требуется выполнить сортировку по одним столбцам по возрастанию, а по другим - по убыванию.
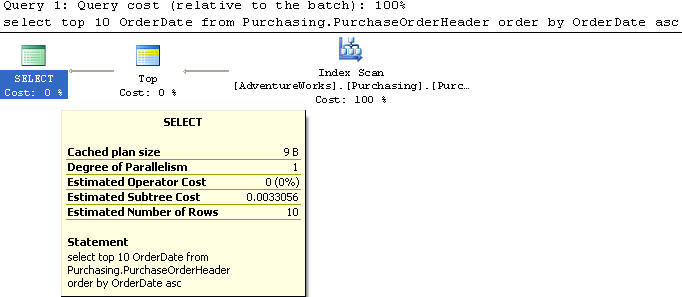
В этом примере мы создаем индекс на OrderDate в возрастающем порядке и SubTotal в возрастающем порядке.
Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и столбцы OrderDate, SubTotal с сортировкой первого и второго по возрастанию.
Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033123.
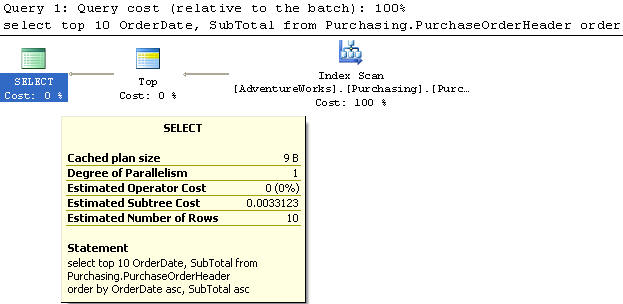
В этом примере мы будем использовать созданный нами индекс с сортировкой по возрастанию обоих столбцов - OrderDate и SubTotal.
Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и столбцы OrderDate, SubTotal с сортировкой первого по возрастанию, а второго - по убыванию.
Запрос выполняет сканирование индекса и имеет стоимость 0,102122. Наличие такого индекса не сильно помогает, поскольку 84% работы приходится на операцию сортировки (Sort).
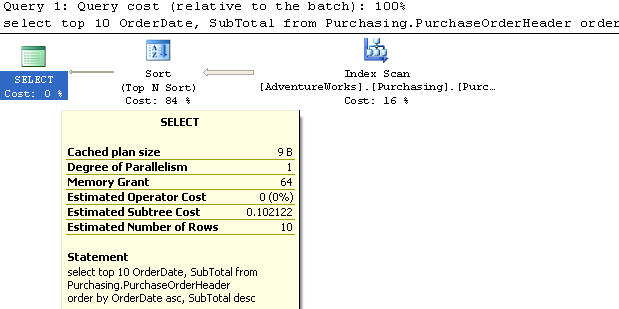
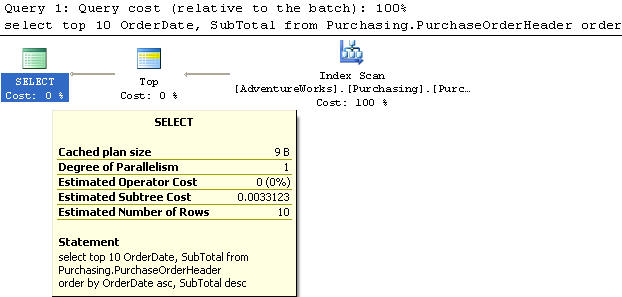
В этом примере мы создали индекс на OrderDate по возрастанию, а на SubTotal - по убыванию.
Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и столбцы OrderDate, SubTotal с сортировкой первого по возрастанию, а второго - по убыванию.
Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033123. Наличие такого индекса значительно помогает, поскольку сортировка не требуется.
Как мы увидели, создание индекса по возрастанию или по убыванию не оказывает большого влияния, когда есть только один столбец, но когда требуется выполнить сортировку данных по двум столбцам в разных направлениях, способ, которым создается индекс, имеет большое значение.
Тестирование выполнялось на SQL Server 2017.
Решение
При создании индекса имеется опция для задания порядка следования значений в индексе. Это может быть сделано просто использованием ключевого слова ASC или DESC при создании индекса, как показано ниже. Все последующие примеры используют демонстрационную базу данных AdventureWorks.
Вот простой код, который демонстрирует создание индекса в убывающем или возрастающем порядке.
Создание индекса в убывающем порядке:
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] DESC );Создание индекса в возрастающем порядке:
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] ASC );Давайте напишем пару запросов и посмотрим их планы, чтобы оценить разницу.
Пример 1
В этом примере мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в возрастающем порядке. Индекса на столбце OrderDate нет.
SELECT TOP 10 OrderDate FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate;Этот запрос выполняет сканирование кластеризованного индекса и имеет стоимость 0,124344.
Пример 2
В этом примере мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в убывающем порядке. Индекса на столбце OrderDate нет.
SELECT TOP 10 OrderDate FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate desc;Этот запрос выполняет сканирование кластеризованного индекса и имеет стоимость 0,124344, как и в предыдущем примере.
Пример 3
В этом примере мы создаем индекс на OrderDate в возрастающем порядке.
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] asc );В этом примере мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в возрастающем порядке.
SELECT TOP 10 OrderDate FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate asc;Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033056, что много лучше предыдущего значения 0,124344.
Таким образом, мы наблюдаем, что добавление индекса делает запрос значительно быстрее.
Пример 4
В этом примере мы снова будем использовать новый индекс на OrderDate в возрастающем порядке.
Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в убывающем порядке.
SELECT TOP 10 OrderDate FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate desc;Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033056, как и в примере 3.
Обратите внимание, что хотя индекс был создан по возрастанию, получение данных в убывающем порядке выполняется так же быстро, как и в возрастающем.
Пример 5
Хотя мы уже видели, что выборка данных в убывающем порядке с индексом по возрастанию не имеет отличий, давайте все же сделаем проверку для уверенности.
В этом примере мы создали индекс на OrderDate в убывающем порядке. Мы удалим индекс и пересоздадим его.
DROP INDEX [IX_PurchaseOrderHeader_OrderDate] ON [Purchasing].[PurchaseOrderHeader];
GO
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] desc );Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и только один столбец OrderDate с сортировкой в возрастающем порядке.
SELECT TOP 10 OrderDate FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate asc;Этот запрос выполняет сканирование нового индекса и имеет стоимость 0,0033056, что совпадает с предыдущим примером; так что нет никаких отличий.
Следует еще проверить случай, когда требуется выполнить сортировку по одним столбцам по возрастанию, а по другим - по убыванию.
Пример 6
В этом примере мы создаем индекс на OrderDate в возрастающем порядке и SubTotal в возрастающем порядке.
DROP INDEX [IX_PurchaseOrderHeader_OrderDate] ON [Purchasing].[PurchaseOrderHeader];
GO
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] ASC, [SubTotal] ASC );Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и столбцы OrderDate, SubTotal с сортировкой первого и второго по возрастанию.
SELECT TOP 10 OrderDate, SubTotal FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate asc, SubTotal asc;Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033123.
Пример 7
В этом примере мы будем использовать созданный нами индекс с сортировкой по возрастанию обоих столбцов - OrderDate и SubTotal.
Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и столбцы OrderDate, SubTotal с сортировкой первого по возрастанию, а второго - по убыванию.
SELECT TOP 10 OrderDate, SubTotal FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate asc, SubTotal desc; Запрос выполняет сканирование индекса и имеет стоимость 0,102122. Наличие такого индекса не сильно помогает, поскольку 84% работы приходится на операцию сортировки (Sort).
Пример 8
В этом примере мы создали индекс на OrderDate по возрастанию, а на SubTotal - по убыванию.
DROP INDEX [IX_PurchaseOrderHeader_OrderDate] ON [Purchasing].[PurchaseOrderHeader];
GO
CREATE NONCLUSTERED INDEX [IX_PurchaseOrderHeader_OrderDate]
ON [Purchasing].[PurchaseOrderHeader] ( [OrderDate] ASC, [SubTotal] DESC ) ;Мы используем таблицу PurchaseOrderHeader, из которой выбираем top 10 записей и столбцы OrderDate, SubTotal с сортировкой первого по возрастанию, а второго - по убыванию.
SELECT TOP 10 OrderDate, SubTotal FROM Purchasing.PurchaseOrderHeader ORDER BY OrderDate asc, SubTotal desc; Этот запрос выполняет сканирование индекса и имеет стоимость 0,0033123. Наличие такого индекса значительно помогает, поскольку сортировка не требуется.
Заключение
Как мы увидели, создание индекса по возрастанию или по убыванию не оказывает большого влияния, когда есть только один столбец, но когда требуется выполнить сортировку данных по двум столбцам в разных направлениях, способ, которым создается индекс, имеет большое значение.
Тестирование выполнялось на SQL Server 2017.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой