
Погружение в SET STATISTICS IO ON для SQL Server
Пересказ статьи Eric Blinn. SQL Server SET STATISTICS IO ON Deep Dive
Проблема
Я использовал параметр STATISTICS IO как средство для настройки производительности SQL Server, однако основное внимание я уделял логическим чтениям. Я вижу здесь значительно больше выходной информации, которую я хотел бы понять и использовать для настройки запросов.
Решение
Опция SET STATISTICS IO ON позволяет вторичному потоку вывода SQL Server включать сведения о том, какие объекты были запрошены запросом и в какой степени. Здесь рассказывается, как читать и реагировать на вывод STATISTICS IO.
Предполагается, что читатель в основном знаком с тем, что такое STATISTICS IO, и как его задействовать. В противном случае обратитесь к этому подготовительному посту.
Все демонстрационные материалы подготовлены на тестовой базе WideWorldImporters под SQL Server 2019. Иллюстрации могут отличаться, но методологически все должно работать и на более старых версиях SQL Server.
Пример STATISTICS IO
Вывод STATISTICS IO включает по одной строке на каждую таблицу в запросе, в которой приводится число "чтений" (reads) разного типа. Каждое "чтение" указывает на считывание запросом 8-килобайтной страницы данных.
Если в пакете имеется несколько запросов, то будут получены несколько независимых списков таблиц.
Если таблица встречается в предложении FROM несколько раз, она будет показана один раз в выводе STATISTICS IO для данного запроса.
Если запрос делается к представлению, то выводиться будет не представление, а лежащие в основе представления таблицы.
Рассмотрим следующие два запроса, выполняемых в одном пакете. В первом используется единственный объект, которым является представление. Второй использует 5 таблиц в предложении FROM, но Application.People повторяется 4 раза.
SELECT TOP 1 * FROM Website.Customers -- Это представление
SELECT TOP 1
si.InvoiceDate
, ap.FullName AccountPersonName
, cp.FullName ContactPersonName
, sp.FullName SalesPersonName
, pp.FullName PackedByPersonName
FROM Sales.Invoices si
INNER JOIN [Application].People ap ON si.AccountsPersonID = ap.PersonID
INNER JOIN [Application].People cp ON si.ContactPersonID = cp.PersonID
INNER JOIN [Application].People sp ON si.SalespersonPersonID = sp.PersonID
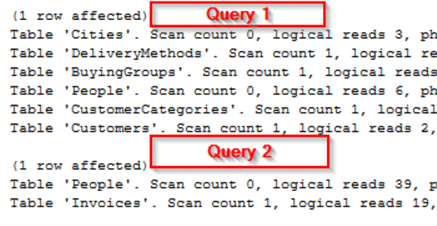
INNER JOIN [Application].People pp ON si.PackedByPersonID = pp.PersonIDСтатистика ввода/вывода для этого пакета запросов показывает:
Для первого запроса - несмотря на единственный объект в предложении FROM - перечислены фактически 6 таблиц, к которым обращался запрос.
Второй запрос - несмотря на перечень 5 таблиц - имеет в выводе только 2 таблицы (поскольку на таблицу People имелось 4 ссылки). Если вы хотите узнать, сколько из этих 39 логических чтений относится к каждому из 4 соединений, то нет надежного способа определить это.
Логические чтения в SQL Server
Логические чтения - это основное выводимое статистическое число, используемое настройщиками производительности. Они видят общее число страниц данных из каждой таблицы, которые необходимы для выполнения запроса.
Если вы видите большие числа, это не обязательно означает, что запрос будет выполняться работать медленно. Однако сокращение этого числа путем модификации запроса или индексных структур часто приводит к улучшению производительности запроса.
Физические чтения
Физическое чтение означает, что страница данных не находилась в буферном пуле во время выполнения запроса и должна быть прочитана с диска. Физические чтения - это подмножество логических чтений. Любая страница, которая прочитана с диска, загружается в буферный пул с тем, чтобы последующие чтения были только логическими.
Эту разницу можно продемонстрировать пакетом запросов, подобным представленному ниже. Следующий запрос включает STATISTICS IO, чистит буферный пул, а затем дважды подряд выполняет один и тот же небольшой запрос.
Замечание. Следует выполнять DBCC DROPCLEANBUFFERS только в окружении, где производительность не важна, т.к. эта команда очищает весь буферный пул.
SET STATISTICS IO ON;
DBCC DROPCLEANBUFFERS;
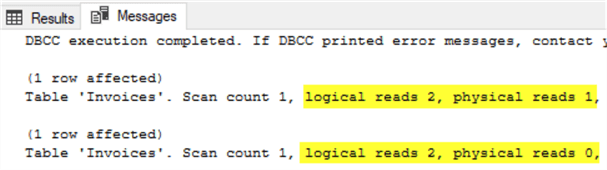
SELECT TOP 1 InvoiceID FROM Sales.Invoices;
SELECT TOP 1 InvoiceID FROM Sales.Invoices;Вывод подтверждает, что первому запросу требуется обратиться к диску (физические чтения), поскольку буферный пул был пуст, в то время как второй запрос мог полагаться исключительно на буферный пул, что потребовало 0 физических чтений. Оба запроса используют одно и то же число логических чтений - 2. Это подтверждает утверждение, что физические чтения являются подмножеством логических чтений, и нет никаких чтений, дополнительных к логическим.
Если при настройке запроса появляется значительное число физических чтений после неоднократного выполнения запроса, это может говорить о том, что экземпляр испытывает недостаток памяти и не может сохранять в буферном пуле необходимое число страниц так долго, как хотелось бы.
Опережающие чтения
Опережающие чтения являются еще одним видом физических чтений, когда SQL Server считывает страницы данных с диска и загружает их в буферный пул. Разница заключается в том, что это происходит до того, как механизм хранилища их запрашивает. Оптимизатор делает это в сценарии, когда он ожидает, что эти страницы, вероятно, потребуются запросу, и он сможет сэкономить время, выполняя чтения заранее. Эти чтения не являются подмножеством логических чтений, т.к. система не может быть уверена, что они всегда будут использованы запросом.
Когда запрос сообщает об опережающих чтениях, это может говорить о проблемах с памятью, т.к. эти физические чтения, вероятно, лучше бы служили логическими чтениями, если бы буферный пул уже содержал загруженными страницы данных.
Neeraj Prasad Sharma написал целую статью, посвященную опережающим чтениям, и как они влияют на производительность. Полезно прочесть.
Чтения LOB
LOB - это сокращение от Large OBject (большой объект). Столбцы считаются LOB, когда они определены с длиной MAX, типа VARCHAR(MAX) или VARBINARY(MAX). XML и данные устаревших типов image и text также являются LOB. Каждый столбец LOB сохраняется на отдельных от остальных столбцов таблицы и индекса страницах. Это позволяет избежать ограничения на длину отдельной строки в 8Кб при загрузке огромного количества данных.
Каждый из типов чтения, рассмотренных до сих пор в этом посте, имеет вариант LOB, который записывает число чтений страниц, выполненных для столбцов LOB.
Запросы, которые используют поколоночные или полнотекстовые индексы, будут также сообщать о чтениях LOB.
Если запрос сообщает о чтениях LOB, оценивайте их так же, как оценивали бы их не-LOB альтернативу, но помните, что LOB-столбцы не индексируются.
Сканирование таблицы и кластеризованного индекса в SQL Server
Наряду с числом чтений, каждая таблица будет включать количество сканирований. Сканирование может означать сканирование таблиц/кластера, но оно может также означать, что сканировалась часть индекса. Следующий пакет запросов включает пример каждого сценария.
SELECT TaxAmount
FROM Sales.InvoiceLines
WHERE TaxAmount < 10; -- не индексировано
SELECT StockItemID
FROM Sales.InvoiceLines
WHERE StockItemID = 44; -- индексированоВ первом запросе рассматриваемый столбец (TaxAmount) не проиндексирован. Для выполнения этого запроса потребуется просканировать весь кластеризованный индекс.
Во втором запросе сравнение выполняется для индексированного столбца (StockItemID). Разумеется, индекс поможет процессору запросов быстро достичь искомой области, где хранится значение, однако потребуется выполнить поблизости сканирование для проверки наличия дубликатов, поскольку кластеризованный индекс не имеет ограничения уникальности.
Этот скриншот планов выполнения для пакета подтверждает сканирование для первого запроса и поиск для второго. Но что будет записано в статистику ввода/вывода?

Скриншот вывода STATISTICS IO говорит несколько иное. Он показывает сканирование для обоих запросов!
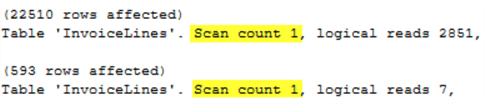
Это доказывает, что "сканирование" в выводе STATISTICS IO не обязательно означает сканирование таблицы/кластера. Фактически, единственным способом избежать сканирования является поиск значения на точное совпадение в индексированном столбце, который также имеет ограничение уникальности.
При настройке запроса количество сканирований 1 не является немедленной причиной тревоги. Обратитесь к плану выполнения за деталями того, какое именно сканирование выполнялось, и действуйте соответствующим образом.
WorkTable, WorkFile и TempDB
Иногда при рассмотрении вывода STATISTICS IO наблюдается таблица, называемая Worktable или Workfile. Это может вызвать недоумение, поскольку такое имя определенно не встречается в предложении FROM или где-либо еще в базе данных! Это означает, что SQL Server использовал, или рассматривал возможность использования, TempDB для временного хранения информации. Часто этой работой является промежуточная сортировка. Работа, которую выполняет TempDB, записывается с упоминанием Worktable и Workfile.
Рассмотрим вызов процедуры. Вывод STATISTICS IO в системе автора использовал 2 страницы TempDB на одном из запросов.
EXEC [Integration].[GetSupplierUpdates] '1/1/2013', '12/31/2013';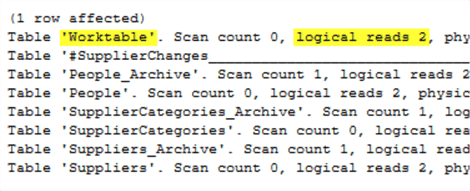
Наличие использования TempDB в пакете запросов не обязательно плохо. Я наблюдал запросы, когда главной таблицей была Worktable. Если это случилось, поищите в плане запроса то, что похоже на сбрасывание в TempDB, и посмотрите, не нужно ли обновить статистику, чтобы получить лучший план без сбрасывания. Поищите также части запроса, выполняющие TOP с ORDER BY или DISTINCT - это как раз те операции, которые могут легко перемещать данные в рабочую таблицу, если задействуется много строк. Также посмотрите, нельзя ли модифицировать эти запросы, чтобы уменьшить число строк перед выполнением операции сортировки.
Работа со сложным выводом STATISTICS IO
При работе с выводом STATISTICS IO для больших пакетов, количество информации может быть огромным. Например, предыдущая демонстрация была однострочным вызовом процедуры, которая дала более 100 строк вывода STATISTICS IO.
Мне нравится использовать сайт StatisticsParser, помогающий осмысливать вывод STATISTICS IO и/или STATISTICS TIME. Этот сайт преобразует текстовый вывод в дружественные пользователю и интерактивные сортируемые таблицы непосредственно в веб-браузере. Внизу также приводятся итоги и расчеты, представляющие процентное отношение общего числа чтений для каждой таблицы в каждом запросе. Сайт работает наилучшим образом, если вы включите и STATISTICS IO, и STATISTICS TIME. Он совершенно бесплатен и невероятно полезен.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой