
Не используйте DISTINCT в качестве "исправления join"
Пересказ статьи Aaron Bertrand. Don’t use DISTINCT as a “join-fixer”
Я спокойно решал проблемы производительности, переписывая медленные запросы, чтобы избежать использования DISTINCT. Зачастую DISTINCT служит лишь для того, чтобы "исправить join", и я могу объяснить что это означает на примере.
Пусть у нас имеется следующая сильно упрощенная схема, представляющая заказчиков, продукты и категории продуктов:
Еще мы имеем таблицу заказов и содержимого заказов:
И некоторые данные:
Маркетинг требует, чтобы мы посылали e-mail или предоставляли код скидки всем тем заказчикам, кто заказал товары из категории beauty. Первоначальная попытка написать запрос могла выглядеть как-то так:
План выглядит не так плохо (пока):
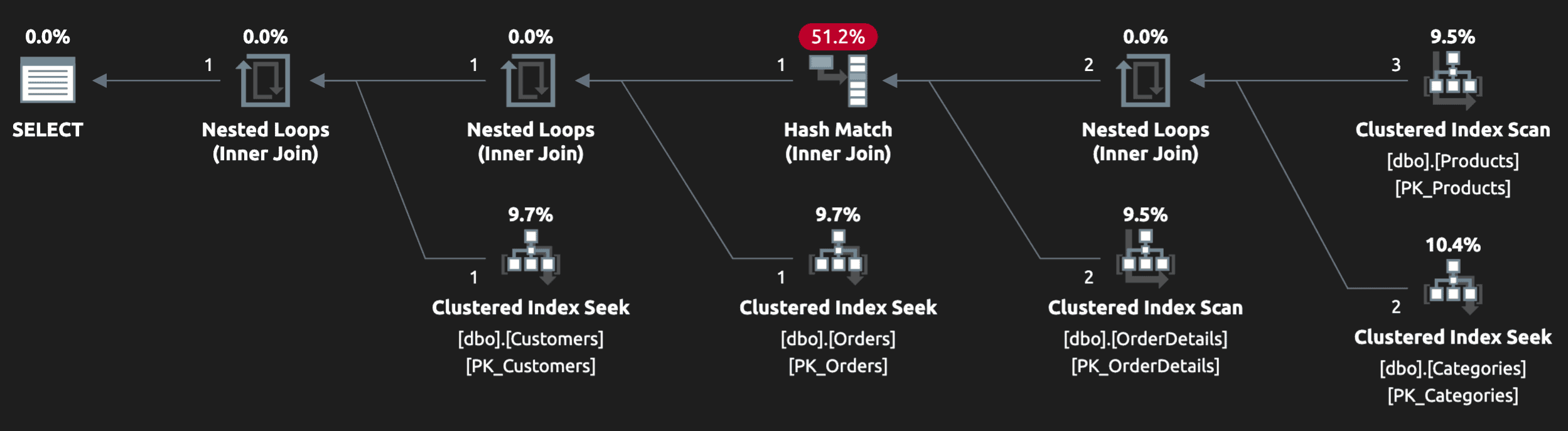
На локальных или тестовых данных вывод может выглядеть правильно, поскольку мы могли вставить по одной строке в OrderDetails, которые отвечают используемому критерию (и наши тесты пройдут проверку). Но что произойдет, если будет два продукта в категории beauty (в одном заказе или по нескольким заказам)?
Теперь запрос вернет этого заказчика дважды! Мы определенно не хотим посылать каждому такому заказчику по два письма или давать несколько скидочных кодов. Сам по себе план фактически не может предоставить доказательства, что имеются дубликаты строк:
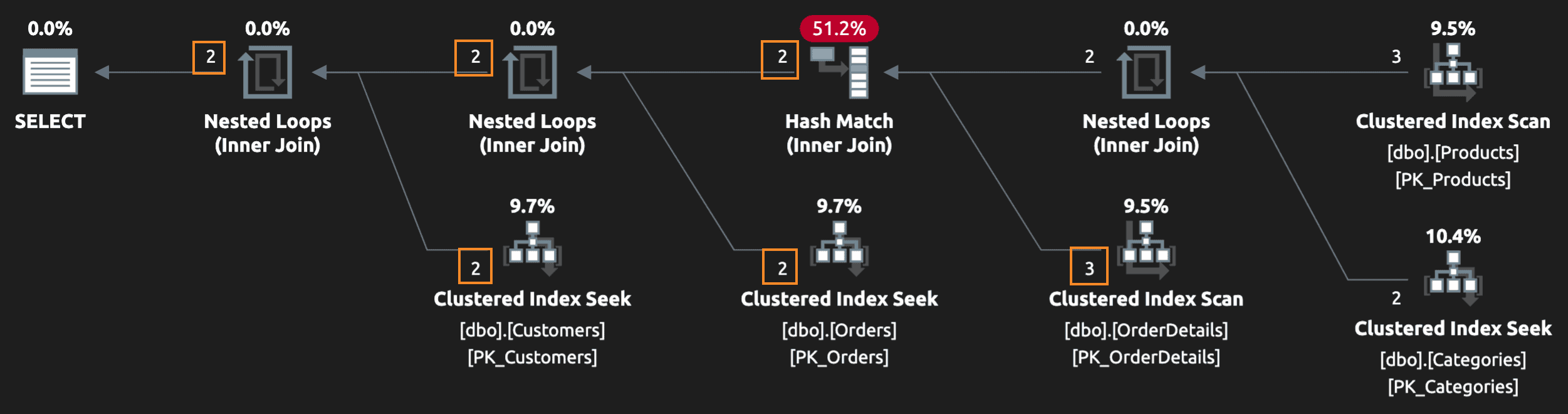
Но вы конечно заметите это, если проверите результаты, или конечный пользователь это заметит, если вы пустите это в продакшен. Быстрое исправление бывает такое: вписать в запрос старину DISTINCT, который на самом деле пофиксит симптомы, устранив дубликаты:
Но какова стоимость? distinct sort, вот что!

Если я тестирую изменения, внесенные в этот запрос, на моем локальном компьютере, это может быть просто тестированием вывода, который быстро возвращает данные, и я могу пропустить ключевое изменение в плане и удовлетвориться добавлением DISTINCT, исправляющего проблему без влияния на производительность.
В то время как мы проводим массу времени, настраивая индексы на всех присутствующих в запросе таблицах, чтобы сделать сортировку менее вредной, это многотабличное соединение всегда будет производить строки, которые никогда не понадобятся. Подумайте о работе SQL Server: да, требуется вернуть корректные результаты, но также требуется сделать это наиболее эффективным способом. Чтение всех данных (а затем сортировать их) только для того, чтобы отбросить некоторые или их большую часть, очень затратно.
Когда я знаю, что требуется соединить таблицы только для проверки наличия строк, а не для вывода из этих таблиц, я перехожу к EXISTS. Я также стараюсь исключить поиск значений, которые, как я знаю, будут одинаковыми в каждой строке. В этом случае мне не требуется всякий раз выполнять соединение с Categories, если CategoryID фактически является константой.
Вот один из способов переписать тот же самый запрос, гарантирующий отсутствие дубликатов заказчиков и, надеюсь, уменьшающий стоимость сортировки:
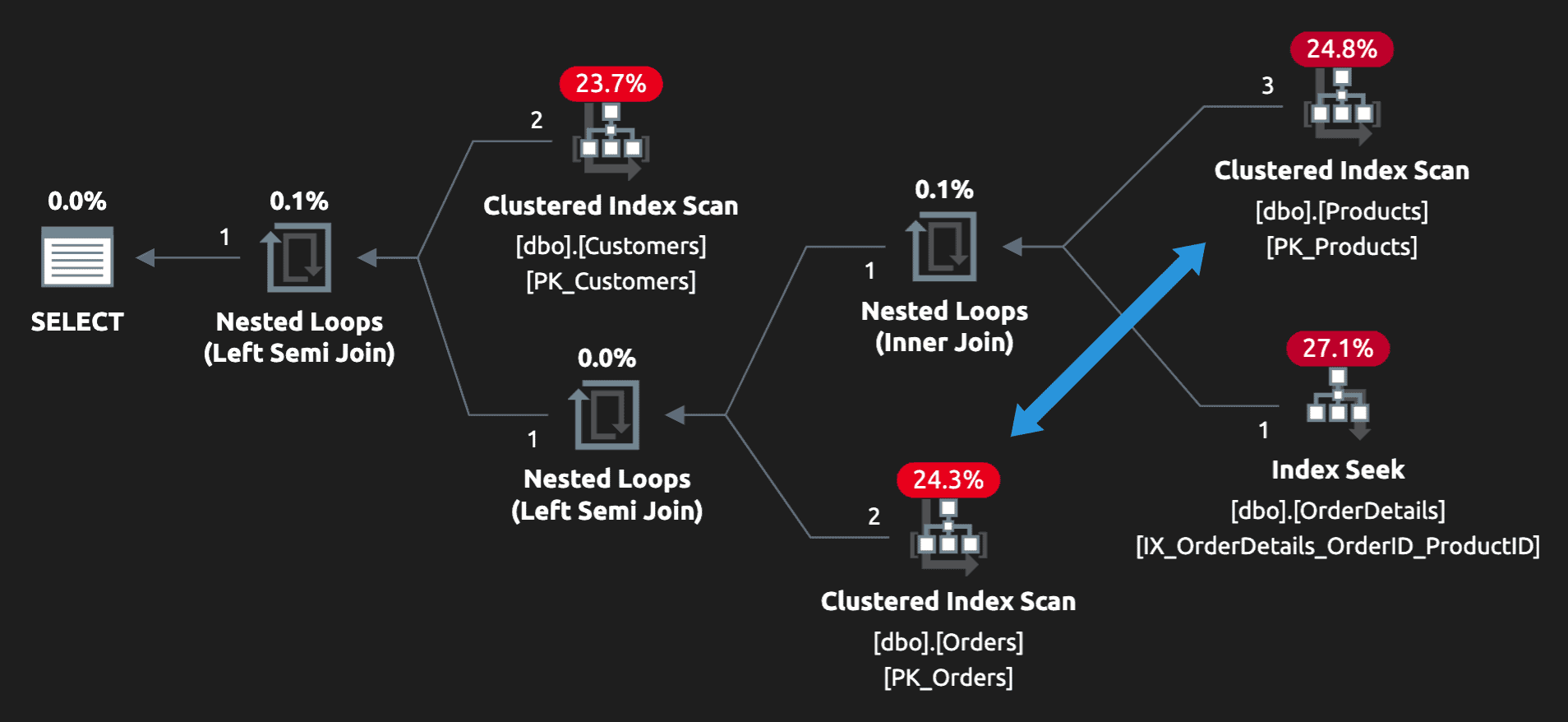
Конечно, тут появляется простой дополнительный поиск в индексе для Categories, но план для всего запроса стал значительно эффективней (мы опустились до 2 сканирований и 2 поисков):

Другим способом написать этот запрос является более позднее сканирование Orders:
Это может дать преимущество, если у вас больше заказов (Orders), чем заказчиков (Customers) (я уверен, что так оно и есть). Обратите внимание на плане, что Orders сканируется позже в надежде, что много не относящихся к делу заказов будет уже отфильтровано.
DISTINCT часто скрывает недостатки используемой логики, и это часто уводит от исследования других способов написания запросов без него. Есть еще один интересный случай использования, о котором я писал несколько лет назад и который показывает, как замена DISTINCT на GROUP BY - хотя это имеет тот же самый смысл и дает одинаковые результаты - может помочь SQL Server легче отфильтровать дубликаты и оказать серьезное влияние на производительность.
Ссылки по теме
1. Предикат EXISTS
2. Как вы можете использовать IS [NOT] DISTINCT FROM
3. COUNT DISTINCT и оконные функции
4. 12 способов переписать запросы SQL для улучшения их производительности
CREATE TABLE dbo.Customers
(
CustomerID int NOT NULL,
Name nvarchar(255) NOT NULL,
CONSTRAINT PK_Customers PRIMARY KEY (CustomerID)
);
CREATE TABLE dbo.Categories
(
CategoryID int NOT NULL,
Name nvarchar(255) NOT NULL,
CONSTRAINT PK_Categories PRIMARY KEY (CategoryID),
CONSTRAINT UQ_Categories UNIQUE (Name)
);
CREATE TABLE dbo.Products
(
ProductID int NOT NULL,
CategoryID int NOT NULL,
Name nvarchar(255) NOT NULL,
CONSTRAINT PK_Products PRIMARY KEY (ProductID)
);Еще мы имеем таблицу заказов и содержимого заказов:
CREATE TABLE dbo.Orders
(
OrderID int NOT NULL,
CustomerID int NOT NULL,
OrderDate date,
OrderTotal decimal(12,2),
CONSTRAINT PK_Orders PRIMARY KEY (OrderID)
);
CREATE TABLE dbo.OrderDetails
(
OrderID int NOT NULL,
LineItemID int NOT NULL,
ProductID int NOT NULL,
Quantity int NOT NULL,
CONSTRAINT PK_OrderDetails PRIMARY KEY (OrderID, LineItemID),
INDEX IX_OrderDetails_OrderID_ProductID (OrderID, ProductID)
);И некоторые данные:
INSERT dbo.Customers (CustomerID, Name)
VALUES (1,N'Aaron'), (2,N'Bob');
INSERT dbo.Categories (CategoryID, Name)
VALUES(1,N'Beauty'), (2,N'Grocery');
INSERT dbo.Products (ProductID, CategoryID, Name)
VALUES (1,1,N'Lipstick'), (2,1,N'Mascara'), (3,2,N'Strawberries');
INSERT dbo.Orders (OrderID, CustomerID, OrderDate, OrderTotal)
VALUES (1,1,getdate(),32.50), (2,2,getdate(),47.05);
INSERT dbo.OrderDetails (OrderID, LineItemID, ProductID, Quantity)
VALUES (1,1,1,5), (2,1,3,10); Маркетинг требует, чтобы мы посылали e-mail или предоставляли код скидки всем тем заказчикам, кто заказал товары из категории beauty. Первоначальная попытка написать запрос могла выглядеть как-то так:
SELECT c.CustomerID, c.Name
FROM dbo.Customers AS c
INNER JOIN dbo.Orders AS o
ON c.CustomerID = o.CustomerID
INNER JOIN dbo.OrderDetails AS od
ON o.OrderID = od.OrderID
INNER JOIN dbo.Products AS p
ON od.ProductID = p.ProductID
INNER JOIN dbo.Categories AS cat
ON p.CategoryID = cat.CategoryID
WHERE cat.Name = N'Beauty';План выглядит не так плохо (пока):
На локальных или тестовых данных вывод может выглядеть правильно, поскольку мы могли вставить по одной строке в OrderDetails, которые отвечают используемому критерию (и наши тесты пройдут проверку). Но что произойдет, если будет два продукта в категории beauty (в одном заказе или по нескольким заказам)?
INSERT dbo.OrderDetails (OrderID, LineItemID, ProductID, Quantity)
VALUES(1,2,2,1);Теперь запрос вернет этого заказчика дважды! Мы определенно не хотим посылать каждому такому заказчику по два письма или давать несколько скидочных кодов. Сам по себе план фактически не может предоставить доказательства, что имеются дубликаты строк:
Но вы конечно заметите это, если проверите результаты, или конечный пользователь это заметит, если вы пустите это в продакшен. Быстрое исправление бывает такое: вписать в запрос старину DISTINCT, который на самом деле пофиксит симптомы, устранив дубликаты:
SELECT DISTINCT c.CustomerID, c.Name
-------^^^^^^^^
FROM dbo.Customers AS c
INNER JOIN dbo.Orders AS o
ON c.CustomerID = o.CustomerID
INNER JOIN dbo.OrderDetails AS od
ON o.OrderID = od.OrderID
INNER JOIN dbo.Products AS p
ON od.ProductID = p.ProductID
INNER JOIN dbo.Categories AS cat
ON p.CategoryID = cat.CategoryID
WHERE cat.Name = N'Beauty';Но какова стоимость? distinct sort, вот что!
Если я тестирую изменения, внесенные в этот запрос, на моем локальном компьютере, это может быть просто тестированием вывода, который быстро возвращает данные, и я могу пропустить ключевое изменение в плане и удовлетвориться добавлением DISTINCT, исправляющего проблему без влияния на производительность.
Будет становиться только хуже с увеличением данных
В то время как мы проводим массу времени, настраивая индексы на всех присутствующих в запросе таблицах, чтобы сделать сортировку менее вредной, это многотабличное соединение всегда будет производить строки, которые никогда не понадобятся. Подумайте о работе SQL Server: да, требуется вернуть корректные результаты, но также требуется сделать это наиболее эффективным способом. Чтение всех данных (а затем сортировать их) только для того, чтобы отбросить некоторые или их большую часть, очень затратно.
Можем ли мы сформулировать запрос без DISTINCT?
Когда я знаю, что требуется соединить таблицы только для проверки наличия строк, а не для вывода из этих таблиц, я перехожу к EXISTS. Я также стараюсь исключить поиск значений, которые, как я знаю, будут одинаковыми в каждой строке. В этом случае мне не требуется всякий раз выполнять соединение с Categories, если CategoryID фактически является константой.
Вот один из способов переписать тот же самый запрос, гарантирующий отсутствие дубликатов заказчиков и, надеюсь, уменьшающий стоимость сортировки:
DECLARE @CategoryID int;
SELECT @CategoryID = CategoryID
FROM dbo.Categories WHERE Name = N'Beauty';
SELECT c.CustomerID, c.Name
FROM dbo.Customers AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.OrderDetails AS od
INNER JOIN dbo.Orders AS o
ON od.OrderID = o.OrderID
INNER JOIN dbo.Products AS p
ON od.ProductID = p.ProductID
WHERE o.CustomerID = c.CustomerID
AND p.CategoryID = @CategoryID
); Конечно, тут появляется простой дополнительный поиск в индексе для Categories, но план для всего запроса стал значительно эффективней (мы опустились до 2 сканирований и 2 поисков):
Другим способом написать этот запрос является более позднее сканирование Orders:
DECLARE @CategoryID int;
SELECT @CategoryID = CategoryID
FROM dbo.Categories WHERE Name = N'Beauty';
SELECT c.CustomerID, c.Name
FROM dbo.Customers AS c
WHERE EXISTS
(
SELECT 1
FROM dbo.Orders AS o
WHERE o.CustomerID = c.CustomerID
AND EXISTS
(
SELECT 1 FROM dbo.OrderDetails AS od
INNER JOIN dbo.Products AS p
ON od.ProductID = p.ProductID
WHERE od.OrderID = o.OrderID
AND p.CategoryID = @CategoryID
)
); Это может дать преимущество, если у вас больше заказов (Orders), чем заказчиков (Customers) (я уверен, что так оно и есть). Обратите внимание на плане, что Orders сканируется позже в надежде, что много не относящихся к делу заказов будет уже отфильтровано.
Заключение
DISTINCT часто скрывает недостатки используемой логики, и это часто уводит от исследования других способов написания запросов без него. Есть еще один интересный случай использования, о котором я писал несколько лет назад и который показывает, как замена DISTINCT на GROUP BY - хотя это имеет тот же самый смысл и дает одинаковые результаты - может помочь SQL Server легче отфильтровать дубликаты и оказать серьезное влияние на производительность.
Ссылки по теме
1. Предикат EXISTS
2. Как вы можете использовать IS [NOT] DISTINCT FROM
3. COUNT DISTINCT и оконные функции
4. 12 способов переписать запросы SQL для улучшения их производительности
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой