
Когда обновляется статистика?
Пересказ статьи Matthew McGiffen. When do Statistics get updated?
Объекты статистики важны, поскольку позволяют SQL сделать хорошие оценки числа строк различных частей рассматриваемого запроса, на основании которых оптимизатор SQL формирует эффективные планы выполнения для получения результатов запроса.
Статистика обновляется автоматически при перестройке (или реорганизации) индекса, на котором она основывается, - но мы обычно перестраиваем индексы только тогда, когда они фрагментированы, а статистика устаревает не в результате фрагментации. Кроме того, имеется много автоматически создаваемых объектов статистики, которые вообще не связаны с индексами.
Обычно рекомендуется включать параметр установки уровня базы данных AUTO_UPDATE_STATISTICS, тогда SQL сможет за вас управлять процессом поддержания статистики в актуальном состоянии. Единственным поводом выключить этот параметр является ваше желание самостоятельно управлять обновлением статистики отличным от данного способом. И вы всегда можете, если потребуется, отключить автоматическое обновление для отдельной таблицы или уровня статистики, а не для всей базы данных.
SQL Server получил возможность автоматического обновления статистики, начиная с версии 7.0. Тем не менее, за долгую карьеру работы с SQL Server всякий раз, когда возникала проблема с производительностью, ответом был призыв «Обновите статистику!» В большинстве случаев оказывалось, что люди на самом деле не понимали, что такое «статистика» или какие механизмы у них имеются для её обновления.
Конечно, SQL Server не совершенен, и иногда требуется вмешательство человеческого разума. Однако чтобы вмешаться, требуется понимать, как это работает.
За кадром SQL учитывает число изменений в таблице, которое может повлиять на статистику. Это могут быть обновления, вставки или удаления. Так, если я вставлю 100 записей, обновлю 100 записей, а затем удалю 100 записей, то получу 300 изменений.
Когда SQL формирует план выполнения запроса, он обращается к различным объектам распределения статистики для оценки числа строк, и использует эту информацию, стараясь найти наилучший план. Объекты статистики, которые он просматривает, называются «интересными» в контексте запроса.
Прежде чем использовать значения статистики, оптимизатор проверит, не "устарела" ли статистика, т.е. не превысил ли счетчик изменений заданное пороговое значение. В этом случае SQL переключится на повторный сбор статистики, прежде чем перейти к построению плана выполнения. Это означает, что план будет сформирован в соответствии с актуальной статистикой для таблицы.
Для последующих запусков запроса, план выполнения будет загружаться из кэша планов. В рамках плана оптимизатор может видеть список объектов статистики, которые были сочтены «интересными» в первую очередь. Опять таки он будет проверять каждый из них на предмет "устаревания". Если они устарели, автоматически будет включен режим обновления объектов статистики, по завершению которого план будет перекомпилирован, т.к. предполагается, что обновленная статистика позволит построить лучший план выполнения. Аналогично, если какой-либо из объектов статистики обновился с момента последнего выполнения, план также будет перекомпилироваться.
Одно важное предостережение - это настройка уровня базы данных AUTO_UPDATE_STATS_ASYNC (асинхронно). Обычно лучшим вариантом является отключение этой настройки в тех случаях, когда наблюдается подобное поведение. Однако если включить её, то в случае устаревшей статистики выполнение запроса не будет дожидаться обновления статистики, а запустит обновление в фоновом режиме во время выполнения. План будет перекомпилироваться на основе новой статистики только при последующем выполнении.
Начиная с SQL Server 2008R2 SP2 и SQL Server 2012 SP1, мы имеем новую динамическую административную функцию (DMF) - sys.dm_db_stats_properties, которая позволяет увидеть, сколько модификаций строк было учтено для данного объекта статистики, а также когда было последнее обновление, сколько строк было отобрано и т.д. Учет модификаций ведется на основе столбца (хотя изначально при введении статистики в SQL Server она подсчитывалась на таблицу). Поэтому счетчик будет меняться только тогда, когда данная операция повлияла на ведущий столбец объекта статистики.
Результаты

В течение долгого времени пороговые значения определялись следующим образом. Статистика считалась устаревшей, если удовлетворялось одно из следующих условий:
Эти пороговые значения означают, что когда таблица содержит большое число строк, статистика может обновляться не так часто. Для таблицы с миллионом строк статистика будет обновляться приблизительно при изменении 200000 строк. В зависимости от распределения данных и вида запроса, это может стать проблемой.
Поэтому в SQL Server 2008R2 SP2 Майкрософт ввела флаг трассировки 2371, который при установке будет уменьшать порог устаревания статистики для больших таблиц. Начиная с SQL Server 2016 эта функциональность принимается по умолчанию.
Это добавляет следующее условие устаревания статистики:
Теперь я собираюсь поправить себя; документация, которую я нашел, УКАЗЫВАЕТ, что порог составляет 25000, но, когда я начал проверять, оказалось, что это совсем не так.
На самом деле кажется, что используется меньшая из двух оценок, т.е.
либо:
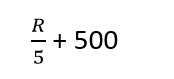
либо:
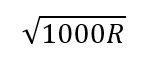
Я не знаю, означает ли это, что обе оценки вычисляются, и используется меньшая, или порог между двумя правилами просто определяется в точке, где вторая формула дает меньший результат, то есть после 19 682 строк. Я нашел этот порог посредством решения уравнения, в котором обе формулы дают один и тот же результат - затем экспериментируя, чтобы доказать это на практике.
Я полагаю, что некорректное утверждение относительно порога в 25000, вероятно, исходит из того, что приблизительное значение (20%) ошибочно принималось за фактическое. Помните, я упоминал, что люди часто делают обобщение, говоря, что статистика устаревает после изменения 20% строк, и забывая о лишних 500 строках. Если бы это было так, то точно 20% дало бы пороговое значение 25000 в качестве точки, где обе формулы дают одинаковый результат.
Так или иначе, это не очень важно знать. Я просто посчитал это интересным! Замечу, что вышеприведенные тесты выполнялись на SQL Server 2012 SP3, поэтому может быть отличие в последующих версиях.
Для более наглядного представления описанных выше правил посмотрите таблицу, в которой приводятся пороговые значения для некоторых размеров таблицы как для старого (Old) алгоритма (без флага трассировки), так и для нового (New) алгоритма (с флагом трассировки или на SQL 2016 и выше).
R - это число строк, когда последний раз собиралась статистика, а T - число изменений, при котором статистика считается устаревшей:
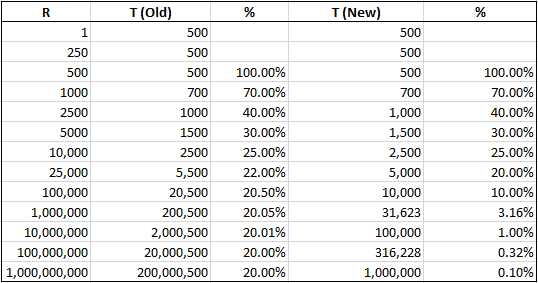
Вы можете увидеть, что для таблиц больших размером разница становится существенной. Если вы пишете запросы к большим таблицам и обновляете статистику вручную, чтобы поддерживать её в актуальном состоянии, то, возможно, вам поможет использование флага трассировки.
Для больших таблиц статистика собирается при обновлении, а не когда необходимо прочитать всю таблицу. Я обсуждал это в следующей статье:
Automatic Sample Sizes for Statistics Updates
Обычно рекомендуется включать параметр установки уровня базы данных AUTO_UPDATE_STATISTICS, тогда SQL сможет за вас управлять процессом поддержания статистики в актуальном состоянии. Единственным поводом выключить этот параметр является ваше желание самостоятельно управлять обновлением статистики отличным от данного способом. И вы всегда можете, если потребуется, отключить автоматическое обновление для отдельной таблицы или уровня статистики, а не для всей базы данных.
SQL Server получил возможность автоматического обновления статистики, начиная с версии 7.0. Тем не менее, за долгую карьеру работы с SQL Server всякий раз, когда возникала проблема с производительностью, ответом был призыв «Обновите статистику!» В большинстве случаев оказывалось, что люди на самом деле не понимали, что такое «статистика» или какие механизмы у них имеются для её обновления.
Конечно, SQL Server не совершенен, и иногда требуется вмешательство человеческого разума. Однако чтобы вмешаться, требуется понимать, как это работает.
Итак, как работает автоматическое обновление статистики?
За кадром SQL учитывает число изменений в таблице, которое может повлиять на статистику. Это могут быть обновления, вставки или удаления. Так, если я вставлю 100 записей, обновлю 100 записей, а затем удалю 100 записей, то получу 300 изменений.
Когда SQL формирует план выполнения запроса, он обращается к различным объектам распределения статистики для оценки числа строк, и использует эту информацию, стараясь найти наилучший план. Объекты статистики, которые он просматривает, называются «интересными» в контексте запроса.
Прежде чем использовать значения статистики, оптимизатор проверит, не "устарела" ли статистика, т.е. не превысил ли счетчик изменений заданное пороговое значение. В этом случае SQL переключится на повторный сбор статистики, прежде чем перейти к построению плана выполнения. Это означает, что план будет сформирован в соответствии с актуальной статистикой для таблицы.
Для последующих запусков запроса, план выполнения будет загружаться из кэша планов. В рамках плана оптимизатор может видеть список объектов статистики, которые были сочтены «интересными» в первую очередь. Опять таки он будет проверять каждый из них на предмет "устаревания". Если они устарели, автоматически будет включен режим обновления объектов статистики, по завершению которого план будет перекомпилирован, т.к. предполагается, что обновленная статистика позволит построить лучший план выполнения. Аналогично, если какой-либо из объектов статистики обновился с момента последнего выполнения, план также будет перекомпилироваться.
Одно важное предостережение - это настройка уровня базы данных AUTO_UPDATE_STATS_ASYNC (асинхронно). Обычно лучшим вариантом является отключение этой настройки в тех случаях, когда наблюдается подобное поведение. Однако если включить её, то в случае устаревшей статистики выполнение запроса не будет дожидаться обновления статистики, а запустит обновление в фоновом режиме во время выполнения. План будет перекомпилироваться на основе новой статистики только при последующем выполнении.
Начиная с SQL Server 2008R2 SP2 и SQL Server 2012 SP1, мы имеем новую динамическую административную функцию (DMF) - sys.dm_db_stats_properties, которая позволяет увидеть, сколько модификаций строк было учтено для данного объекта статистики, а также когда было последнее обновление, сколько строк было отобрано и т.д. Учет модификаций ведется на основе столбца (хотя изначально при введении статистики в SQL Server она подсчитывалась на таблицу). Поэтому счетчик будет меняться только тогда, когда данная операция повлияла на ведущий столбец объекта статистики.
SELECT
s.name AS StatsName, sp.*
FROM sys.stats s
CROSS apply sys.dm_db_stats_properties(s.OBJECT_ID, s.stats_id) sp
WHERE s.name = 'IX_Test_TextValue'Результаты
Итак, что такое пороговые значения?
В течение долгого времени пороговые значения определялись следующим образом. Статистика считалась устаревшей, если удовлетворялось одно из следующих условий:
- Размер таблицы вырос с 0 строк на ненулевое число строк.
- В таблице было не более 500 строк при последнем сборе статистики, и с тех пор произошло более 500 модификаций.
- В таблице было более 500 строк при последнем сборе статистики, и число модификаций превысило 500 + 20% от числа строк при последнем сборе статистики (когда речь идет о таблицах с большим количеством строк, во многих документах это описывается просто как 20%, поскольку дополнительные 500 становятся все менее и менее значимыми по сравнению с тем числом, с которым вы имеете дело).
Эти пороговые значения означают, что когда таблица содержит большое число строк, статистика может обновляться не так часто. Для таблицы с миллионом строк статистика будет обновляться приблизительно при изменении 200000 строк. В зависимости от распределения данных и вида запроса, это может стать проблемой.
Поэтому в SQL Server 2008R2 SP2 Майкрософт ввела флаг трассировки 2371, который при установке будет уменьшать порог устаревания статистики для больших таблиц. Начиная с SQL Server 2016 эта функциональность принимается по умолчанию.
Это добавляет следующее условие устаревания статистики:
- Если число строк (R) на момент повледнего сбора статистики составляет 25000 или более, и число модификаций превышает корень квадратный из R x 1000:
Теперь я собираюсь поправить себя; документация, которую я нашел, УКАЗЫВАЕТ, что порог составляет 25000, но, когда я начал проверять, оказалось, что это совсем не так.
На самом деле кажется, что используется меньшая из двух оценок, т.е.
либо:
либо:
Я не знаю, означает ли это, что обе оценки вычисляются, и используется меньшая, или порог между двумя правилами просто определяется в точке, где вторая формула дает меньший результат, то есть после 19 682 строк. Я нашел этот порог посредством решения уравнения, в котором обе формулы дают один и тот же результат - затем экспериментируя, чтобы доказать это на практике.
Я полагаю, что некорректное утверждение относительно порога в 25000, вероятно, исходит из того, что приблизительное значение (20%) ошибочно принималось за фактическое. Помните, я упоминал, что люди часто делают обобщение, говоря, что статистика устаревает после изменения 20% строк, и забывая о лишних 500 строках. Если бы это было так, то точно 20% дало бы пороговое значение 25000 в качестве точки, где обе формулы дают одинаковый результат.
Так или иначе, это не очень важно знать. Я просто посчитал это интересным! Замечу, что вышеприведенные тесты выполнялись на SQL Server 2012 SP3, поэтому может быть отличие в последующих версиях.
Для более наглядного представления описанных выше правил посмотрите таблицу, в которой приводятся пороговые значения для некоторых размеров таблицы как для старого (Old) алгоритма (без флага трассировки), так и для нового (New) алгоритма (с флагом трассировки или на SQL 2016 и выше).
R - это число строк, когда последний раз собиралась статистика, а T - число изменений, при котором статистика считается устаревшей:
Вы можете увидеть, что для таблиц больших размером разница становится существенной. Если вы пишете запросы к большим таблицам и обновляете статистику вручную, чтобы поддерживать её в актуальном состоянии, то, возможно, вам поможет использование флага трассировки.
Для больших таблиц статистика собирается при обновлении, а не когда необходимо прочитать всю таблицу. Я обсуждал это в следующей статье:
Automatic Sample Sizes for Statistics Updates
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой