
Эмпирический взгляд на Key Lookup
Forrest. An Empirical Look at Key Lookups
Я исхожу из того, что вы знакомы с понятием поиска ключа (key lookup), и для чего он нужен.

Оптимизатор на базе стоимости в SQL Server ненавидит их, поскольку считает, что они выполняют чтение случайным образом с вращающегося диска - что маловероятно для современного корпоративного сервера. Я заинтересовался тем, насколько плохи эти предположения на практике.
Установка
Я собираюсь здесь использовать тестовую таблицу с миллионом строк фиктивных данных. Я буду тестировать на моем ноутбуке со стандартным SSD и процессором Intel с переменной тактовой частотой (для этих тестов в среднем немного ниже 4GHz).
CREATE TABLE dbo.InternetRecipes (
ID INT IDENTITY PRIMARY KEY,
Calories INT,
SizeOfIntro INT,
RecipeName NVARCHAR(300)
)
INSERT dbo.InternetRecipes
SELECT TOP (1000000)
(ROW_NUMBER() OVER(ORDER BY 1/0))%1000,
(ROW_NUMBER() OVER(ORDER BY 1/0))%10000+500,
'Paleo Fat Free Cotton Candy'
FROM master..spt_values a,
master..spt_values b
--С включенными столбцами и без них для тестирования
CREATE INDEX IX_InternetRecipes_Calories
ON dbo.InternetRecipes(Calories)
CREATE INDEX IX_InternetRecipes_Calories_incl
ON dbo.InternetRecipes(Calories)
INCLUDE (RecipeName)Сравнение времени/стоимости
Используя индексный хинт, мы можем непосредственно сравнить планы с поиском ключа и без него. План "без" использует индекс, который включает RecipeName. Обычно это называют покрывающим индексом, но сегодня я назову его "включающим" индексом.
--7.7 баксов запроса
SELECT RecipeName
FROM dbo.InternetRecipes WITH(INDEX(IX_InternetRecipes_Calories_incl))
WHERE Calories >= 0
AND RecipeName = 'Vegan Steak'
--200 баксов запроса
SELECT RecipeName
FROM dbo.InternetRecipes WITH(INDEX(IX_InternetRecipes_Calories))
WHERE Calories >= 0
AND RecipeName = 'Vegan Steak'
OPTION(MAXDOP 1)Всплывают некоторые интересные детали. Первое: стоимость keylookup масштабируется нелинейно.
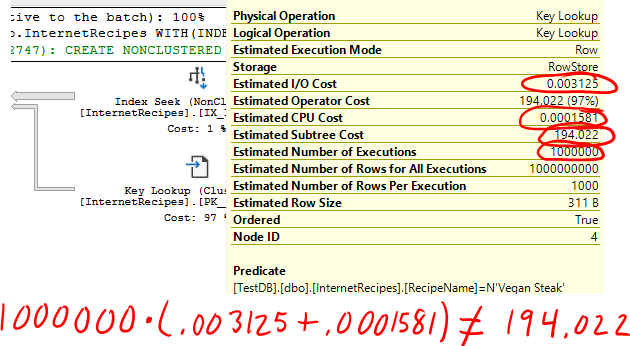
Простая математика показывает, что при стоимости в миллион ЦП только 11495 приходится на операции ввода-вывода. Кстати, 11495 - это число страниц данных в таблице. Стоимость ввода-вывода Key Lookup скрывается за числом страниц в таблице, хотя вряд ли это происходит в действительности. Конечно, следующим, что я должен был протестировать, было попадание в интервал, и эксперименты показали, что стоимость поиска ключа не предполагает, что каждый из них вызывает ввод-вывод.
Однако точная формула все еще ускользает от меня. Я думаю, что это восхитительно занудная проблема, которая никого не волнует, поэтому я постараюсь вскоре над ней поработать.
Запрос на один миллион поисков ключа оценивается более чем в 26 раз по сравнением с простым поиском, и в 18 раз дольше по времени выполнения. Оптимизатор здесь неплохо справляется! Или нет? Я запускал тест с прогретым кэшем, что если мы проигнорируем стоимость ввода-вывода?
--MS посмеется над вами, если это поломает сервер
DBCC SETIOWEIGHT(0)Оптимизатор оценивает увеличение соотношения стоимости до 149 раз (в то время как фактическое время выполнения, конечно, остается 18 раз). Несмотря на то, что фактическое выполнение не требует ввода-вывода, оптимизатор запросов, включая затраты на ввод-вывод, справляется лучше.
Давайте поправим эту вещь, связанную со стоимостью ввода-вывода…
DBCC SETIOWEIGHT(1)И тест с непрогретым кэшем...
CHECKPOINT --Как если мы только что создали таблицу/индексы
DBCC DROPCLEANBUFFERS --повторить при необходимостиКоэффициент времени выполнения составил около 15 с вводом-выводом - не сильно изменилось. Если я заблокирую чтение вперед флагом трассировки 9115 (спасибо, Пол), коэффициент времени снизится до 17 раз, а стоимость запроса останется неизменной. Итак, оптимизатор выполняет приличную работу по расчету стоимости между включающим индексом и планом с поиском ключей, но только тогда, когда он предполагает затраты на ввод-вывод..
Тестирование точки перехода
Поскольку SQL Server так сильно ненавидит поиск ключа, он иногда предпочитает выбор сканирования всей таблицы, чтобы избежать этого. По моему опыту, это происходит слишком рано. Могу ли я доказать это?
Давайте удалим включающий индекс, и выберем результаты во временную переменную для тестирования.
DROP INDEX IX_InternetRecipes_Calories_incl
ON dbo.InternetRecipes
SELECT RecipeName
FROM dbo.InternetRecipes
WHERE Calories >= 996
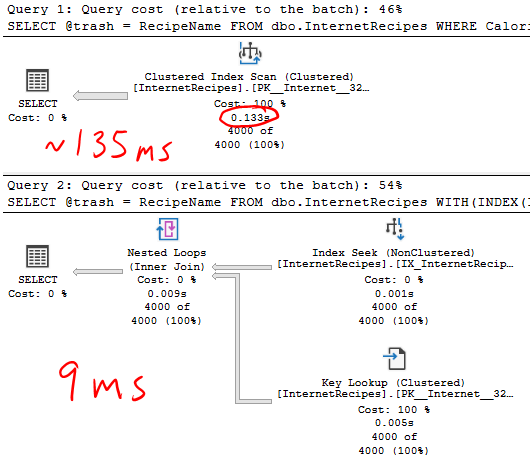
OPTION(MAXDOP 1);Я обнаружил, что точка перехода находится между значениями Calories 996 и 997, что соответствует 3000 и 4000 строк для поиска ключа.
План с полным сканированием занимает в среднем 135 мс, в то время как план с поиском ключа для 4000 строк только 9 мс.
Истинный переломный момент наступает только тогда, когда значение Calories равно 925 или 75К строк, и план с поиском ключа занимает столько же времени, сколько сканирование. Даже при тестировании с непрогретым кэшем точка перехода составляет 41К строк. Итак, на моем ноутбуке с прогретым кэшем оптимизатор переключился на сканирование только на 4% оптимального числа строк, или в 25 раз раньше (примерно).
Тестирование пропускной способности
О каком еще влиянии поиска ключа мы можем узнать? Давайте запихнем это в цикл, и установим очень высоким число повторений цикла.
Сначала вернем включающий индекс.
CREATE INDEX IX_InternetRecipes_Calories_incl
ON dbo.InternetRecipes(Calories)
INCLUDE (RecipeName)Теперь общая структура цикла:
DECLARE @i INT = 0
DECLARE @trash NVARCHAR(300)
DECLARE @dt DATETIME2 = SYSDATETIME()
WHILE @i < 10000
BEGIN
SELECT TOP(1000) @trash = RecipeName
FROM dbo.InternetRecipes WITH(INDEX(IX_InternetRecipes_Calories))
WHERE Calories = 666 --дьявольский тортик
OPTION(MAXDOP 1);
SET @i += 1
END
SELECT DATEDIFF(MILLISECOND,@dt,SYSDATETIME())Используя TOP для ограничения числа строк/поисков, я измеряю, сколько времени занимает выполнение цикла из 10К запросов. Вот мои усредненные значения:
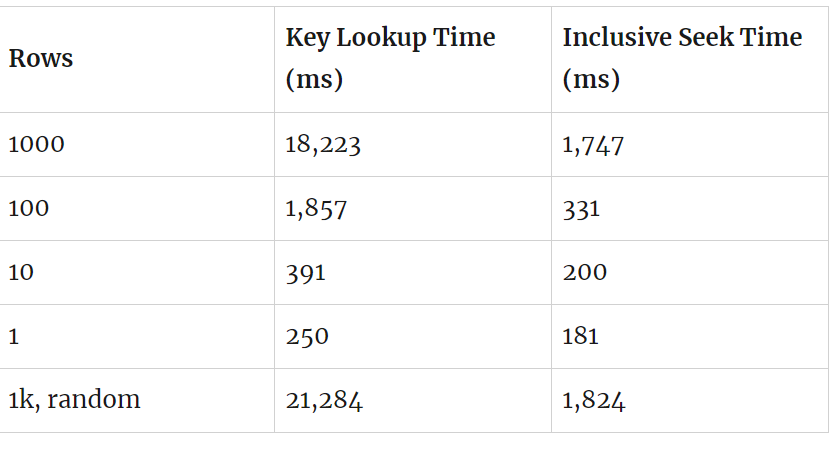
Эти числа специфичны для моего ноутбука и конкретного теста. И все же я вижу, что влияние поиска ключа становится все сильнее. В этом есть смысл, т.к. имеются некоторые накладные расходы, связанные с запросом.
Если предположить, что все избыточное время в тесте на 1000 строк обусловлено поисками, я получу значение приблизительно 1,6 микросекунд на поиск. Для сравнения: чтобы задействовать дополнительное ядро ЦП, потребуется 600 000 поисков в секунду.
Мне стало любопытно, использовало ли повторное значение нечестное преимущество кеш-памяти процессора, поэтому я также выполнил тесты со случайными значениями Calories, которые показали незначительное замедление. При этих условиях (вероятно, более представительный производственный сервер) дополнительное ядро потребовало бы 514К поисков в секунду. И большое предостережение: все эти тесты используют структуру с единственной таблицей и запускаются на персональном ноутбуке.
Выводы
Поиск ключа ухудшает производительность, но, вероятно, не так сильно, как вы думаете, и определенно не так сильно, как думает оптимизатор при определении точки перехода поиск/сканирование. Если вы видите пугающий процент стоимости у key lookup, помните, что это, вероятно, выброс.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой