
Изучаем PostgreSQL вместе с Grant Fritchey: введение в VACUUM
Пересказ статьи Grant Fritchey. Learning PostgreSQL With Grant Introducing VACUUM
Хотя имеется много функций в PostgreSQL, которые действительно подобны имеющимся в SQL Server, есть и несколько уникальных. Одна из этих уникальных функций называется VACUUM. Для себя я сравниваю ее с tempdb в SQL Server. Не потому, что она действует подобным образом или служит подобным целям. Абсолютно нет. Просто потому, что обе они фундаментальны с точки зрения поведения соответствующих систем, обе достаточно сложны в своей работе, в том, что они делают, и в способах, которыми мы можем их испортить.
VACUUM - это сложная, глубокая тема, поэтому эта статья является лишь введением в нее. Я должен следить за новыми статьями, вникая в различное поведение этого процесса. Однако давайте начнем. VACUUM, и тесно связанный с ним ANALYZE, являются жизненно важными процессами для нормальной работы среды PostgreSQL. Большую часть времени они работают в автоматической режиме, и вам никогда не придется иметь с ними дела непосредственно. Однако поскольку эти процессы настолько важны, я собираюсь сделать их обзор.
В своей основе VACUUM довольно прост. PostgreSQL фактически, физически, не удаляет данные, когда вы выполняете оператор DELETE. Напротив, эти данные логически внутренне помечаются как удаленные и не показываются при запросе данных из таблицы. Для оператора UPDATE новая строка добавляется, а старая - логически помечается как удаленная. Как вы можно догадаться, если ничего не предпринимать, ваша база данных со временем заполнит весь диск (если вы не определите TABLESPACE для таблиц и ограничите его размер, но это тема другой статьи). Тогда первой функцией VACUUM является удаление этих строк из таблицы. Вот так. Хорошо и просто.
Ну, конечно, не так все просто.
У VACUUM есть второе поведение, называемое ANALYZE. Процесс ANALYZE проверяет таблицы и индексы, генерирует статистику, а затем сохраняет эту информацию в системном каталоге (системной таблице), который называется pg_statistic. Коротко говоря, VACUUM ANALYZE в PostgreSQL - это эквивалент UPDATE STATISTICS в SQL Server.
Я говорил, что VACUUM был одновременно сложен и является неотъемлемой частью поведения PostgreSQL. Без него вы не только заполните свои носители, но и не будете иметь актуальной статистики. В процессе VACUUM заключено еще больше вариантов поведения, но мы не собираемся здесь описывать их все. Фактически мы даже не собираемся очень глубоко погружаться в эти два стандартных поведения, очистки ваших таблиц и обслуживания статистики, поскольку каждое из них является само по себе глубокой темой. Мы собираемся пройтись по основам работы этих процессов и тому, почему вам следует уделять им внимание.
Выполнить работу VACUUM очень просто. Эта команда будет гарантировать освобождение пространства всех ваших таблиц:
В то время как пространство удаленных строк освобождается для повторного использования, фактический размер вашей базы данных не сжимается. Исключение составляет наличие совершенно пустых страниц в хвостовой части таблицы. В этом случае вы можете наблюдать, что пространство полностью возвращено.
Эквивалентом SHRINK в PostgreSQL будет выполнение такой команды:
Эта команда перестроит все таблицы в базе данных в новые таблицы. Это сопровождается значительными накладными расходами и будет с большой вероятностью вызывать блокировку во время перемещения данных. Это также вызовет значительный рост ввода/вывода в системе. Однако это удалит каждую пустую страницу, возвращая пространство операционной системе. Опять, как в случае SHRINK, регулярное выполнение этой команды не считается хорошей практикой. Ключевой проблемой при выполнении этой команды является то, что стандартные автоматические процессы VACUUM блокируются, возможно, вынуждая вас запускать этот процесс снова, и снова, и... Ну, вы поняли.
Вы можете также указать конкретные таблицы при выполнении VACUUM вручную:
Вы можете даже указать список таблиц:
В любом случае вместо доступа к каждой таблице в базе данных, на которые я имею разрешения, только перечисленная таблица или таблицы пройдут процесс очистки VACUUM.
Чтобы на самом деле увидеть, что происходит, мы можем воспользоваться дополнительным параметром VERBOSE. Я собираюсь загрузить в таблицу некоторые данные, а затем удалить их. Затем мы выполним VACUUM:
Вот результаты (ваши могут несколько отличаться, но должны быть похожи):
Я не на 100% понимаю все, что здесь происходит; как говорит эта серия, учимся вместе. Тем не менее, есть вполне понятная информация. 11998 кортежей удалено при оставшихся 3004. Вы также можете видеть страницы индекса pkcountry, в котором было 77 страниц, но 58 были удалены, а 7 осталось. Вдобавок ко всему этому в конце вы получаете метрики производительности, сколько времени это заняло и задействованный ввод-вывод. Это все полезная информация.
Для тех, кто следит за этой серией, если вы захотите почистить вашу таблицу после этого небольшого теста, вот скрипты, которые я использовал:
Я мог бы снова выполнить VACUUM на этой таблице, чтобы увидеть результаты.
Теперь тут просто тонны метрик с подробностями обо всем, что делает VACUUM и как он это делает. Однако это основы. Давайте двинемся дальше и уделим некоторое внимание ANALYZE.
То, в чем PostgreSQL согласуется с SQL Server, это использование статистики на таблицах как средство оценки числа строк в процессе оптимизации запроса. И, как и в SQL Server, эта статистика может устареть со временем при изменении данных. Хотя имеется автоматизированный процесс для обработки статистики (об этом позже), вы можете решить, как и в SQL Server, что требуется непосредственное вмешательство. Поэтому в процесс VACUUM встроена возможность обновлять статистику с помощью параметра ANALYZE:
Как и в случае с командой VACUUM в начале, будут проверены все таблицы, к которым у меня есть доступ в пределах базы данных, и для них будет выполнена команда ANALYZE.
Интересно, что вы можете выполнить ANALYZE как отдельный процесс. При этом будут выполнены те же самые действия, что и для предыдущего оператора:
Вы можете выполнять команды порознь, главным образом, в качестве механизма контроля и настройки. Выполняемые действия те же самые. Чтобы это увидеть, я хочу посмотреть на таблицу radio.countries и ее статистику после выполнения ANALYZE для подтверждения того, что это отразилось на двух строках таблицы:
Теперь, как и в случае SQL Server, имеется целая куча статистики. Я вывожу здесь только гистограмму, чтобы мы могли увидеть, какого сорта данные могут в ней содержаться. Вот результаты:
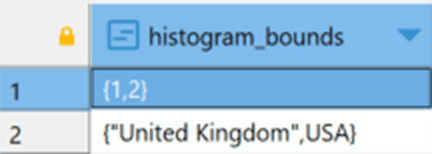
Я собираюсь снова выполнить представленный выше скрипт загрузки данных, а затем сразу снова посмотреть статистику в pg_stats. Поскольку тут используется автоматический процесс VACUUM (об этом позже), который по умолчанию запускается примерно раз в минуту, я хочу увидеть статистику прежде, чем она будет исправлена автоматическим процессом ANALYZE:
Первый результирующий набор (без картинки) из pg_stats в точности соответствует представленному выше. Это потому, что автоматический процесс VACUUM еще не выполнил ANALYZE, и я не выполнял вручную ANALYZE. Затем, конечно, я выполнил ANALYZE, и результаты гистограммы изменились следующим образом:

Отсюда просто продолжаются значения в гистограмме для таблицы (опять оставим обсуждение этого для следующей статьи).
Я могу также применить параметр VERBOSE, чтобы увидеть происходящее, когда выполняется ANALYZE. Теперь я просто выполню команду ANALYZE:
Вот вывод:
Вы можете увидеть, что сейчас сканируется меньший набор строк для получения нового набора статистик и новой гистограммы. Вы также можете увидеть удаленные строки в выводе. Я выполнял это порознь, с тем чтобы не делать и VACUUM, и ANALYZE. Так вы можете разделить эти вещи и получить непосредственный контроль.
Я обещал это несколько раз в статье. Существует автоматический процесс VACUUM, который нам необходимо обсудить, демон автовакуумации.
В PostgreSQL имеется включенный по умолчанию процесс демона, который будет автоматически запускать на ваших базах данных оба процесса VACUUM и ANALYZE. Этот процесс довольно сложный и настраиваемый, посредством чего вы можете внести существенные изменения в базовое поведение.
По сути автовакуумация выполняется на каждой базе данных на сервере. Число одновременно задействованных потоков по умолчанию равно 3, что устанавливается посредством параметра autovacuum_max_workers, который вы можете настраивать. По умолчанию он запускается каждые 60 секунд, и устанавливается значением autovacuum_naptime, которое вы тоже можете настраивать. Вы увидите шаблон, большинство параметров которого можно настроить.
Потом имеется пороговое значение, определяющее, следует ли данной таблице подвергнуться процессам VACUUM и ANALYZE. VACUUM должен превзойти значение autovacuum_vacuum_threshold, которым по умолчанию является 50 кортежей, или строк. Это немного сложнее, потому что используются вычисления, вовлекающие autovacuum_vacuum_insert_threshold, составляющее по умолчанию 1000 кортежей, которое затем добавляется к autovacuum_vacuum_insert_scale_factor, представляющее по умолчанию 20% строк данной таблицы. Затем это значение умножается на число кортежей в таблице. Все это позволяет нам узнать, какие таблицы будут подвергнуты процессу VACUUM. Вы можете увидеть эту формулу в документации.
Подобное имеет место для ANALYZE. autovacuum_analyze_threshold, 50 кортежей по умолчанию, вычисляется по autovacuum_analyze_scale_factor, 10% таблицы, и числу строк для получения порогового значения.
Всеми эти настройками можно управлять на уровне сервера или на уровне таблицы, обеспечивая высокую степень контроля над тем, как именно работают автоматический VACUUM и автоматический ANALYZE. Подобно обновлению статистики в SQL Server, вы можете обнаружить, что автоматизированные процессы потребуется либо настраивать, либо дополнять время от времени ручным обновлением. Как утверждалось выше, статистика в PostgreSQL предоставляет оптимизатору информацию того же вида, что и в SQL Server, поэтому очень важно сделать ее как можно более правильной.
Как я говорил в начале, процесс VACUUM является очень большой и ответственной темой. Это введение затронуло ее только по верхам. Тем не менее, это основы. Мы имеем автоматический, или ручной, процесс, который вычищает удаленные кортежи. Далее мы имеем автоматический, или ручной, процесс, который обеспечивает нас актуальной статистикой. Хотя взять под контроль эти процессы и настроить автоматическое поведение или запустить их вручную относительно просто, знание того, когда и где вносить корректировки, — это совершенно другой уровень знаний.
Ссылки по теме
1. Введение в управление параллелизмом в PostgreSQL
2. PostgreSQL (auto) vacuum - уже не тайна
3. PostgreSQL для администраторов SQL Server: первые четыре настройки для проверки
Процесс PostgreSQL VACUUM
В своей основе VACUUM довольно прост. PostgreSQL фактически, физически, не удаляет данные, когда вы выполняете оператор DELETE. Напротив, эти данные логически внутренне помечаются как удаленные и не показываются при запросе данных из таблицы. Для оператора UPDATE новая строка добавляется, а старая - логически помечается как удаленная. Как вы можно догадаться, если ничего не предпринимать, ваша база данных со временем заполнит весь диск (если вы не определите TABLESPACE для таблиц и ограничите его размер, но это тема другой статьи). Тогда первой функцией VACUUM является удаление этих строк из таблицы. Вот так. Хорошо и просто.
Ну, конечно, не так все просто.
У VACUUM есть второе поведение, называемое ANALYZE. Процесс ANALYZE проверяет таблицы и индексы, генерирует статистику, а затем сохраняет эту информацию в системном каталоге (системной таблице), который называется pg_statistic. Коротко говоря, VACUUM ANALYZE в PostgreSQL - это эквивалент UPDATE STATISTICS в SQL Server.
Я говорил, что VACUUM был одновременно сложен и является неотъемлемой частью поведения PostgreSQL. Без него вы не только заполните свои носители, но и не будете иметь актуальной статистики. В процессе VACUUM заключено еще больше вариантов поведения, но мы не собираемся здесь описывать их все. Фактически мы даже не собираемся очень глубоко погружаться в эти два стандартных поведения, очистки ваших таблиц и обслуживания статистики, поскольку каждое из них является само по себе глубокой темой. Мы собираемся пройтись по основам работы этих процессов и тому, почему вам следует уделять им внимание.
VACUUM
Выполнить работу VACUUM очень просто. Эта команда будет гарантировать освобождение пространства всех ваших таблиц:
VACUUM;В то время как пространство удаленных строк освобождается для повторного использования, фактический размер вашей базы данных не сжимается. Исключение составляет наличие совершенно пустых страниц в хвостовой части таблицы. В этом случае вы можете наблюдать, что пространство полностью возвращено.
Эквивалентом SHRINK в PostgreSQL будет выполнение такой команды:
VACUUM (FULL);Эта команда перестроит все таблицы в базе данных в новые таблицы. Это сопровождается значительными накладными расходами и будет с большой вероятностью вызывать блокировку во время перемещения данных. Это также вызовет значительный рост ввода/вывода в системе. Однако это удалит каждую пустую страницу, возвращая пространство операционной системе. Опять, как в случае SHRINK, регулярное выполнение этой команды не считается хорошей практикой. Ключевой проблемой при выполнении этой команды является то, что стандартные автоматические процессы VACUUM блокируются, возможно, вынуждая вас запускать этот процесс снова, и снова, и... Ну, вы поняли.
Вы можете также указать конкретные таблицы при выполнении VACUUM вручную:
VACUUM radio.antenna;Вы можете даже указать список таблиц:
VACUUM radio.antenna, radio.bands, radio.digitalmodes;В любом случае вместо доступа к каждой таблице в базе данных, на которые я имею разрешения, только перечисленная таблица или таблицы пройдут процесс очистки VACUUM.
Чтобы на самом деле увидеть, что происходит, мы можем воспользоваться дополнительным параметром VERBOSE. Я собираюсь загрузить в таблицу некоторые данные, а затем удалить их. Затем мы выполним VACUUM:
INSERT INTO radio.countries
(country_name)
SELECT generate_series(1,15000,1);
DELETE FROM radio.countries
WHERE country_id BETWEEN 3 AND 12000;
VACUUM (VERBOSE) radio.countries;Вот результаты (ваши могут несколько отличаться, но должны быть похожи):
vacuuming "hamshackradio.radio.countries"
finished vacuuming "hamshackradio.radio.countries": index scans: 1
pages: 0 removed, 81 remain, 81 scanned (100.00% of total)
tuples: 11998 removed, 3004 remain, 0 are dead but not yet removable
removable cutoff: 1305, which was 0 XIDs old when operation ended
new relfrozenxid: 1304, which is 3 XIDs ahead of previous value
index scan needed: 64 pages from table (79.01% of total) had 11998 dead item identifiers removed
index "pkcountry": pages: 77 in total, 58 newly deleted, 65 currently deleted, 7 reusable
avg read rate: 12.169 MB/s, avg write rate: 12.169 MB/s
buffer usage: 729 hits, 3 misses, 3 dirtied
WAL usage: 388 records, 0 full page images, 96719 bytes
system usage: CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 sЯ не на 100% понимаю все, что здесь происходит; как говорит эта серия, учимся вместе. Тем не менее, есть вполне понятная информация. 11998 кортежей удалено при оставшихся 3004. Вы также можете видеть страницы индекса pkcountry, в котором было 77 страниц, но 58 были удалены, а 7 осталось. Вдобавок ко всему этому в конце вы получаете метрики производительности, сколько времени это заняло и задействованный ввод-вывод. Это все полезная информация.
Для тех, кто следит за этой серией, если вы захотите почистить вашу таблицу после этого небольшого теста, вот скрипты, которые я использовал:
DELETE FROM radio.countries
WHERE country_id > 2;
ALTER TABLE radio.countries
ALTER COLUMN country_id RESTART WITH 3;Я мог бы снова выполнить VACUUM на этой таблице, чтобы увидеть результаты.
Теперь тут просто тонны метрик с подробностями обо всем, что делает VACUUM и как он это делает. Однако это основы. Давайте двинемся дальше и уделим некоторое внимание ANALYZE.
ANALYZE
То, в чем PostgreSQL согласуется с SQL Server, это использование статистики на таблицах как средство оценки числа строк в процессе оптимизации запроса. И, как и в SQL Server, эта статистика может устареть со временем при изменении данных. Хотя имеется автоматизированный процесс для обработки статистики (об этом позже), вы можете решить, как и в SQL Server, что требуется непосредственное вмешательство. Поэтому в процесс VACUUM встроена возможность обновлять статистику с помощью параметра ANALYZE:
VACUUM (ANALYZE);Как и в случае с командой VACUUM в начале, будут проверены все таблицы, к которым у меня есть доступ в пределах базы данных, и для них будет выполнена команда ANALYZE.
Интересно, что вы можете выполнить ANALYZE как отдельный процесс. При этом будут выполнены те же самые действия, что и для предыдущего оператора:
ANALYZE;Вы можете выполнять команды порознь, главным образом, в качестве механизма контроля и настройки. Выполняемые действия те же самые. Чтобы это увидеть, я хочу посмотреть на таблицу radio.countries и ее статистику после выполнения ANALYZE для подтверждения того, что это отразилось на двух строках таблицы:
VACUUM (ANALYZE) radio.countries;
SELECT
ps.histogram_bounds
FROM
pg_stats AS ps
WHERE
ps.tablename = 'countries';Теперь, как и в случае SQL Server, имеется целая куча статистики. Я вывожу здесь только гистограмму, чтобы мы могли увидеть, какого сорта данные могут в ней содержаться. Вот результаты:
Я собираюсь снова выполнить представленный выше скрипт загрузки данных, а затем сразу снова посмотреть статистику в pg_stats. Поскольку тут используется автоматический процесс VACUUM (об этом позже), который по умолчанию запускается примерно раз в минуту, я хочу увидеть статистику прежде, чем она будет исправлена автоматическим процессом ANALYZE:
INSERT INTO radio.countries
(country_name)
SELECT generate_series(1,15000,1);
SELECT
ps.histogram_bounds
FROM
pg_stats AS ps
WHERE
ps.tablename = 'countries';
VACUUM (ANALYZE) radio.countries;
SELECT
ps.histogram_bounds
FROM
pg_stats AS ps
WHERE
ps.tablename = 'countries';Первый результирующий набор (без картинки) из pg_stats в точности соответствует представленному выше. Это потому, что автоматический процесс VACUUM еще не выполнил ANALYZE, и я не выполнял вручную ANALYZE. Затем, конечно, я выполнил ANALYZE, и результаты гистограммы изменились следующим образом:
Отсюда просто продолжаются значения в гистограмме для таблицы (опять оставим обсуждение этого для следующей статьи).
Я могу также применить параметр VERBOSE, чтобы увидеть происходящее, когда выполняется ANALYZE. Теперь я просто выполню команду ANALYZE:
DELETE FROM radio.countries
WHERE country_id BETWEEN 3 AND 12000;
ANALYZE (VERBOSE) radio.countries;Вот вывод:
analyzing "radio.countries"
"countries": scanned 81 of 81 pages, containing 3004 live rows and 11998 dead rows; 3004 rows in sample, 3004 estimated total rowsВы можете увидеть, что сейчас сканируется меньший набор строк для получения нового набора статистик и новой гистограммы. Вы также можете увидеть удаленные строки в выводе. Я выполнял это порознь, с тем чтобы не делать и VACUUM, и ANALYZE. Так вы можете разделить эти вещи и получить непосредственный контроль.
Я обещал это несколько раз в статье. Существует автоматический процесс VACUUM, который нам необходимо обсудить, демон автовакуумации.
Автовакуумация (Autovacuum)
В PostgreSQL имеется включенный по умолчанию процесс демона, который будет автоматически запускать на ваших базах данных оба процесса VACUUM и ANALYZE. Этот процесс довольно сложный и настраиваемый, посредством чего вы можете внести существенные изменения в базовое поведение.
По сути автовакуумация выполняется на каждой базе данных на сервере. Число одновременно задействованных потоков по умолчанию равно 3, что устанавливается посредством параметра autovacuum_max_workers, который вы можете настраивать. По умолчанию он запускается каждые 60 секунд, и устанавливается значением autovacuum_naptime, которое вы тоже можете настраивать. Вы увидите шаблон, большинство параметров которого можно настроить.
Потом имеется пороговое значение, определяющее, следует ли данной таблице подвергнуться процессам VACUUM и ANALYZE. VACUUM должен превзойти значение autovacuum_vacuum_threshold, которым по умолчанию является 50 кортежей, или строк. Это немного сложнее, потому что используются вычисления, вовлекающие autovacuum_vacuum_insert_threshold, составляющее по умолчанию 1000 кортежей, которое затем добавляется к autovacuum_vacuum_insert_scale_factor, представляющее по умолчанию 20% строк данной таблицы. Затем это значение умножается на число кортежей в таблице. Все это позволяет нам узнать, какие таблицы будут подвергнуты процессу VACUUM. Вы можете увидеть эту формулу в документации.
Подобное имеет место для ANALYZE. autovacuum_analyze_threshold, 50 кортежей по умолчанию, вычисляется по autovacuum_analyze_scale_factor, 10% таблицы, и числу строк для получения порогового значения.
Всеми эти настройками можно управлять на уровне сервера или на уровне таблицы, обеспечивая высокую степень контроля над тем, как именно работают автоматический VACUUM и автоматический ANALYZE. Подобно обновлению статистики в SQL Server, вы можете обнаружить, что автоматизированные процессы потребуется либо настраивать, либо дополнять время от времени ручным обновлением. Как утверждалось выше, статистика в PostgreSQL предоставляет оптимизатору информацию того же вида, что и в SQL Server, поэтому очень важно сделать ее как можно более правильной.
Заключение
Как я говорил в начале, процесс VACUUM является очень большой и ответственной темой. Это введение затронуло ее только по верхам. Тем не менее, это основы. Мы имеем автоматический, или ручной, процесс, который вычищает удаленные кортежи. Далее мы имеем автоматический, или ручной, процесс, который обеспечивает нас актуальной статистикой. Хотя взять под контроль эти процессы и настроить автоматическое поведение или запустить их вручную относительно просто, знание того, когда и где вносить корректировки, — это совершенно другой уровень знаний.
Ссылки по теме
1. Введение в управление параллелизмом в PostgreSQL
2. PostgreSQL (auto) vacuum - уже не тайна
3. PostgreSQL для администраторов SQL Server: первые четыре настройки для проверки
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой