
Давайте спроектируем индекс вместе
Пересказ статьи Erik Darling. Let’s Design An Index Together
Часть 1
Только один индекс
Я хочу ускорить оба следующих запроса:
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 4
AND p.LastActivityDate >= '20120101'
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.LastActivityDate >= '20110101'
ORDER BY p.Score DESC;
Поработайте над этим, прежде чем читать дальше.
Часть 2
Давным-давно
Я просил вас спроектировать один индекс, чтобы ускорить оба запроса.
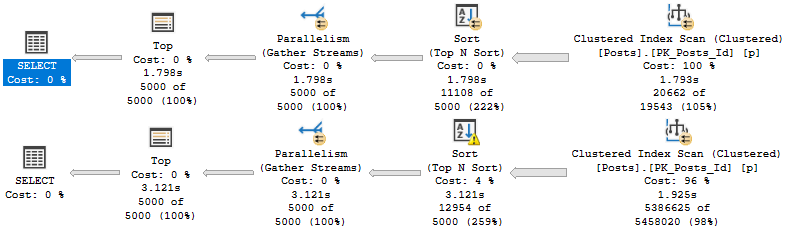
Если мы посмотрим планы без предложенных индексов, то увидим, почему они требуют настройки.
Получите работу
Для обоих запросов оптимизатор скажет об "отсутствующих индексах". Я взял эти слова в кавычки, потому что я бы не пропустил этот индекс.
Зеленый экран
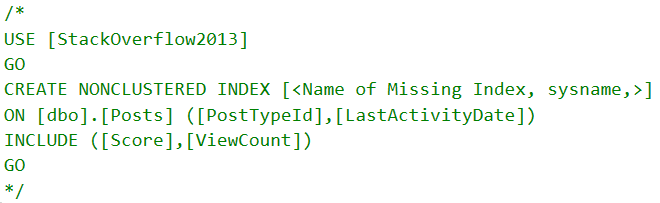
Если мы добавим его, результаты смешаются, как дешевый виски.
Продолжим движение
Конечно, здесь есть некоторое улучшение, но ни один запрос не ускорился. Второй запрос выполняет много работы для сортировки данных.
Есть предположение, что если мы перестанем это делать, наш запрос можно сделать быстрей.
Давайте остановимся и подумаем: Что мы сортируем?
Конечно, это та штука в order by: Score DESC.
Куда теперь?
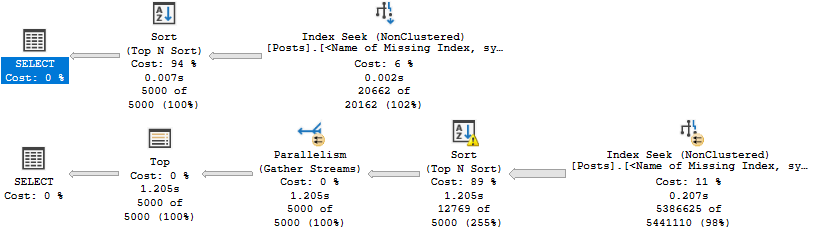
Похоже, что предположение о пропущенном индексе было неверным. Score не следует делать включенным столбцом.
Столбцы в списке включенных упорядочиваются только по столбцам в ключе индекса.
Если мы хотим избавиться от этой сортировки, нам нужно сделать ее ключевым столбцом.
Но где?
Продолжим работу, прежде чем читать дальше.
Часть 3
Теперь нам нужно выяснить, как это выправить. Для этого нам потребуется немного повозиться с индексом.
Сейчас мы имеем такой:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, LastActivityDate)
INCLUDE(Score, ViewCount);
Этот индекс прекрасно работает, если нам нужно отсортировать небольшое число данных.
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 4
AND p.LastActivityDate >= '20120101'
ORDER BY p.Score DESC;
Имеется только 25К строк со значением PostTypeId = 4. С этим легко справиться.
Проблема здесь:
SELECT TOP (5000)
p.LastActivityDate,
p.PostTypeId,
p.Score,
p.ViewCount
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.LastActivityDate >= '20110101'
ORDER BY p.Score DESC;
Имеется 6000223 строки с PostTypeId = 1 - и это проблема.
Не позволяйте мне начинать с PostTypeId = 2 - это ответ - который имеет 11091349 строк.
Управление изменениями
Большинство народа попытается сначала сделать индекс, который начинается с Score. Даже при том, что он не находится в предложении WHERE, чтобы помочь нам найти данные, индекс, который помещает Score первым по порядку, кажется заманчивым решением нашей проблемы.
CREATE INDEX whatever
ON dbo.Posts(Score DESC, PostTypeId, LastActivityDate)
INCLUDE(ViewCount)
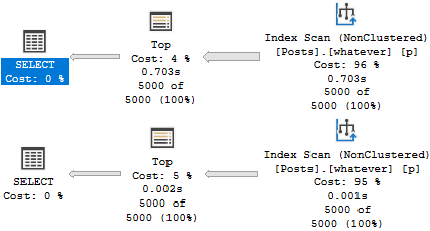
Результат весьма успешен. Оба плана кажутся довольно быстрыми, и мы можем остановиться на этом, но мы упустили бы ключевой момент в индексах B-Tree.
Не так плохо
Что немного смущает, если говорить о скорости, так это количество операций чтения, которые мы делаем, чтобы найти наши данные.
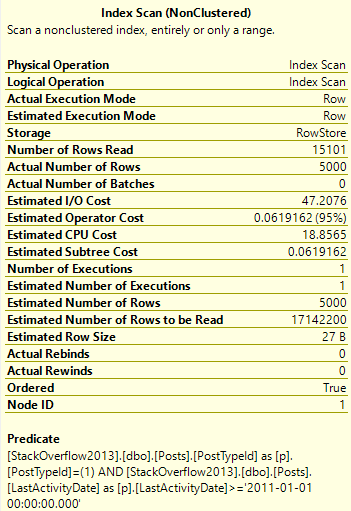
Сканирование
Нам нужно прочитать только 15К строк, чтобы найти 5000 топовых вопросов - помните, что они очень распространены.
Нам нужно прочитать много больше строк, чтобы найти top 5000...что бы 4 ни означало.
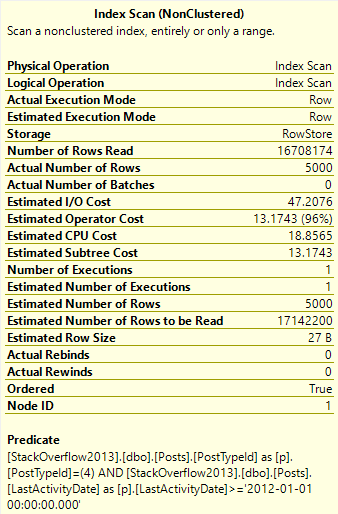
Воображаемые читатели
Читается почти весь индекс, чтобы найти эти типы постов.
Встретимся в середине
Если мы остановимся, то упустим тот момент, что, когда мы добавляем столбцы в индекс B-Tree, то индекс сначала упорядочивается по первому столбцу ключа. Если он не уникален, то упорядочивается второй столбец в пределах каждого диапазона значений.
Суммируя сказанное, давайте немного изменим наш индекс:
CREATE INDEX whatever
ON dbo.Posts(PostTypeId, Score DESC, LastActivityDate)
INCLUDE(ViewCount) WITH (DROP_EXISTING = ON);
понимая, что поиск в единственном столбце PostTypeId приведет нас к упорядоченному столбцу Score в этом диапазоне значений.
Теперь наши планы выглядят так:
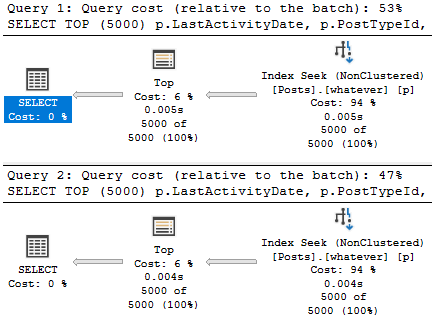
Это позволяет нам как избежать сортировки, так и удержать число чтений на минимуме.
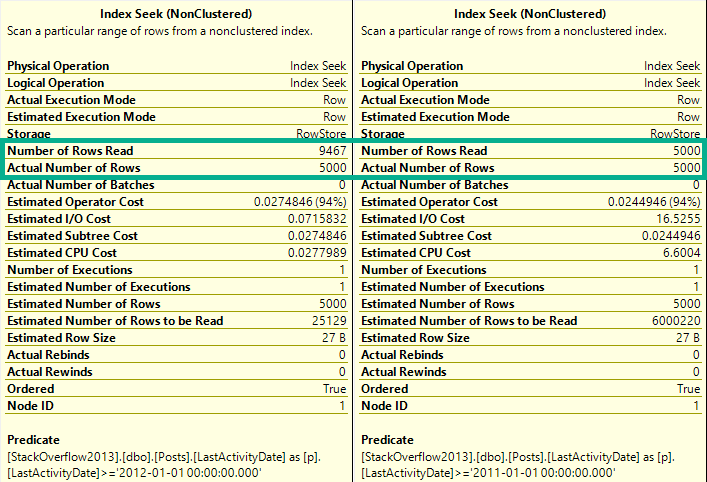
Мало чтений
Заключение
При проектировании индексов важно не упускать из вида назначение запросов. Часто в первую очередь должны учитываться предикаты.
В других случаях нам необходимо принимать во внимание упорядочивание и группировку. Например, если мы используем оконные функции производительность может оказаться неприемлемой без индексирования элементов partition by и order by, и нам может потребоваться переместить другие столбцы в те части индекса, которые могут показаться далеко не идеальными.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой