
Что такое план выполнения и как его найти в PostgreSQL
Пересказ статьи Henrietta Dombrovskaya. What Is an Execution Plan and How to Find It in PostgreSQL
В последнем блоге (Когда настройка параметра в PostgreSQL не помогает) мы сравнили несколько планов выполнения для оператора SQL по мере изменения параметров и индексов. При этом не было упомянуто то, что собой представляет план выполнения, как можно получить план выполнения запроса и как интерпретировать результат. В этом блоге мы глубже погрузимся в эту тему.
Зачем нам нужен план выполнения?
Весьма вероятно, что если вы когда-нибудь работали с любой реляционной СУБД, то слышали термин "план выполнения" и, более того, могли их видеть. Но думали ли вы о том, зачем вам может понадобиться план выполнения для оператора SQL? Почему вам никогда не нужно было получать план выполнения для программ на Си или Java? Причина состоит в том, что SQL является декларативным языком. Это означает, что когда мы пишем оператор SQL, мы описываем результат, который требуется получить, а не то, как должен быть получен этот результат.
В императивных языках (например, Си) мы, напротив, указываем что делать для получения желаемого результата, т.е. последовательность шагов, которые должны быть выполнены. Иногда это не выглядит подобным образом при использовании современных языков, но после компиляции они обычно выполняют действия, на которые вы их запрограммировали.
Замечание: если вы хотите выполнять примеры, в последнем разделе статьи находится приложение с инструкциями для подготовки демонстрации.
Что такое план выполнения?
Итак, мы просто отправляем оператор SQL для выполнения его в PostgreSQL. Давайте использовать тот же самый оператор, который мы использовали для иллюстрации в предыдущей статье.
SELECT f.flight_no,
f.actual_departure,
count(passenger_id) passengers
FROM postgres_air.flight f
JOIN postgres_air.booking_leg bl
ON bl.flight_id = f.flight_id
JOIN postgres_air.passenger p
ON p.booking_id=bl.booking_id
WHERE f.departure_airport = 'JFK'
AND f.arrival_airport = 'ORD'
AND f.actual_departure BETWEEN
'2023-08-08' and '2023-08-12'
GROUP BY f.flight_id, f.actual_departure;Мы посылаем его на выполнение в PostgreSQL - что происходит затем?
Для получения результатов запроса PostgreSQL выполняет следующие шаги:
- Компиляция и преобразование оператора SQL в выражение, состоящее из высокоуровневых логических операций, известных как логический план.
- Оптимизирует логический план и преобразует его в план выполнения.
- Выполняет (интерпретирует) план и возвращает результаты.
Компиляция запроса SQL подобна компиляции кода, написанного на императивном языке. Исходный код разбирается, и генерируется внутреннее представление. Однако компиляция операторов SQL имеет два существенных отличия.
Во-первых, в императивных языках определения идентификаторов обычно включаются в исходный код, тогда как определения объектов, на которые имеются ссылки в запросах SQL, хранятся, главным образом, в базе данных. Соответственно смысл запроса зависит от структуры базы данных: разные серверы базы данных могут интерпретировать по-разному один и тот же запрос.
Во-вторых, выходом компилятора императивного языка обычно (почти всегда) является исполняемый код, такой как байт-код для виртуальной машины Java. Напротив, выходом компилятора запроса является выражение, состоящее из высокоуровневых операций, которые остаются декларативными - Они не дают никаких инструкций относительно того, как получить требуемый вывод. Тут задается возможный порядок операций, но не способ выполнения этих операций. Логический план для оператора SQL, представленного выше, приводится ниже:
project f.flight_no, f.actual_departure, count(p.passenger_id)[] (
group [f.flight_no, f.actual_departure] (
filter [f.departure_airport = 'JFK'] (
filter [f.arrival_airport = 'ORD'] (
filter [f.actual_departure >='2023-08-08'](
filter [f.actual_departure <='2023-08-12' ] (
join [bl.flight_id = f.flight_id] (
access (flights f),
join(bl.booking_id=p.booking_id (
access (booking_leg bl),
access (passenger p)
))))))))Здесь project означает реляционную операцию
проекции, которая сокращает число выводимых столбцов: filter означает реляционную операцию фильтрации, которая применяет критерии отбора, join означает операцию соединения, access указывает, что нам необходимо прочитать данные из таблиц базы данных. Заметим, что представление выше является "очеловеченной" версией внутреннего представления PostgreSQL, и не существует команды, которая позволила бы вам "увидеть" его реально.Инструкции как выполнить запрос появляются на следующей стадии обработки запроса - оптимизации. Оптимизатор выполняет преобразования двух типов: он заменяет логические операции своими алгоритмами выполнения и, возможно, изменяет структуру логического выражения, меняя порядок, в котором будут выполняться логические операции.
Затем он пытается найти логический план и физические операции, которые минимизируют требуемые ресурсы, включая время выполнения. В этом блоге мы не будем вникать в детали того, как эти преобразования выполняются и как оптимизатор решает, какой план является лучшим, но мы рассмотрим несколько примеров в последующих блогах. Единственное, что нам нужно знать сейчас, что выводом оптимизатора является выражение, содержащее физические операции. Это выражение называется (физическим) планом выполнения. По этой причине оптимизатор PostgreSQL часто называют планировщиком запросов. Есть множество способов получить физический план выполнения запроса, которые будут описаны далее в блоге.
Наконец, план выполнения запроса интерпретируется движком выполнения запросов, который часто называют исполнителем (executor) в сообществе пользователей PostgreSQL, и его вывод возвращается клиентскому приложению.
Как строится план выполнения?
Работа оптимизатора - построить лучший из возможных физический план, который реализует заданный логический план на сервере, на котором он исполняется. Это сложный процесс: иногда сложная логическая операция заменяется множеством физических операций, или несколько логических операций сливаются в единственную физическую операцию.
Чтобы построить план, оптимизатор использует правила преобразования, эвристику и алгоритмы оптимизации на базе стоимости. Правило преобразует план в другой план с лучшей стоимостью. Например, операции фильтрации и проекции уменьшают размер набора данных и, следовательно, должны выполняться как можно раньше, правило может переупорядочить операции так, чтобы операции фильтрации и проекции выполнялись раньше.
Алгоритм оптимизации выбирает план с наименьшей оценочной стоимостью. Число возможных планов (называемых пространством планов) для запроса, содержащим несколько операций, является огромным - слишком большим, чтобы алгоритм рассмотрел каждый возможный план, поэтому используются эвристики для сокращения числа планов, оцениваемых оптимизатором.
Как получить план выполнения?
Существует много способов получить план выполнения любого оператора SQL, не только SELECT, но и INSERT, UPDATE и DELETE.
Самый легкий способ - выполнить команду EXPLAIN и передать в нее оператор SQL:
EXPLAIN SELECT f.flight_no,
f.actual_departure,
count(passenger_id) passengers
FROM postgres_air.flight f
JOIN postgres_air.booking_leg bl
ON bl.flight_id = f.flight_id
JOIN postgres_air.passenger p
ON p.booking_id=bl.booking_id
WHERE f.departure_airport = 'JFK'
AND f.arrival_airport = 'ORD'
AND f.actual_departure BETWEEN
'2023-08-08' and '2023-08-12'
GROUP BY f.flight_id, f.actual_departure;Результатом будет предполагаемый план выполнения. Помните, что в отличие от Oracle или MS SQL Server, планировщик запросов PostgreSQL всегда создает план выполнения непосредственно перед выполнением самого запроса на основе множества факторов, включая текущую статистику базы данных. (Другие платформы РСУБД могут повторно использовать ранее вычисленные планы, что может оказать как отрицательное, так и положительное влияние.)
Когда вы выполняете EXPLAIN, PostgreSQL рассчитывает стоимость операций на основе имеющейся статистики, которая может не быть актуальной (или, по меньшей мере, может находиться в другом состоянии, когда вы фактически выполняете ваш запрос, чтобы получить данные). Тем не менее, выполнение команды EXPLAIN должно дать вам хорошее представление о том, как будет выполняться запрос.
Другой версией команды EXPLAIN является EXPLAIN ANALYZE:
EXPLAIN ANALYZE SELECT f.flight_no,
f.actual_departure,
count(passenger_id) passengers
FROM postgres_air.flight f
JOIN postgres_air.booking_leg bl
ON bl.flight_id = f.flight_id
JOIN postgres_air.passenger p
ON p.booking_id=bl.booking_id
WHERE f.departure_airport = 'JFK'
AND f.arrival_airport = 'ORD'
AND f.actual_departure BETWEEN
'2023-08-08' and '2023-08-12'
GROUP BY f.flight_id, f.actual_departure;Эта команда производит план выполнения и выполняет оператор (но не выводит результаты его выполнения). Это позволяет нам увидеть не только предварительную статистику, но и то, как долго выполнялся запрос на самом деле и какие исходные оценки были ошибочными.
Наконец, вы можем выполнить команду EXPLAIN с несколькими параметрами, которые перечислены ниже:
- ANALYZE [ Boolean ] – включает фактическое выполнение.
- VERBOSE [ Boolean ] - дает более подробную информацию о шагах плана.
- COSTS [ Boolean ] - параметр COSTS по умолчанию установлен в TRUE, и включает фактическое значение, когда указан ANALYZE - отображает предварительную и фактическую стоимость каждого узла плана (операции в запросе).
- SETTINGS [ Boolean ] - список измененных конфигурационных параметров.
- BUFFERS [ Boolean ] – используется только при включенном ANALYZE, показывает использование общих буферов.
- WAL [ Boolean ] – используется только при включенном ANALYZE, показывает влияние WAL (сначала запись в журнал).
- TIMING [ Boolean ] – используется только при включенном ANALYZE, показывает время выполнения для каждого узла плана запроса.
- SUMMARY [ Boolean ] – значение по умолчанию TRUE, при включенном ANALYZE печатает итоговую информацию.
- FORMAT { TEXT | XML | JSON | YAML } – формат вывода плана выполнения.
В качестве примера вы можете использовать следующее:
EXPLAIN ( ANALYZE, VERBOSE, FORMAT XML )
SELECT…и получить физический план выполнения с подробными деталями в формате XML. Вы можете найти больше информации на странице SQL Explain в документации PostgreSQL. Но EXPLAIN и EXPLAIN ANALYZE будут двумя командами, которые вы обычно будете использовать чаще всего.
Как читать план выполнения?
Теперь давайте, наконец, вернемся к планам выполнения, которые мы анализировали в предыдущей статье. Планы выполнения были получены при использовании команд EXPLAIN (ANALYSE, BUFFERS, TIMING). Поскольку здесь мы фокусируемся на понимании плана выполнения как такового, получим более компактную версию плана, используя команду EXPLAIN без дополнительных параметров.

Рис.1. План выполнения
План выполнения представлен в виде дерева физических операций. В этом дереве узлы представляют операции, а стрелки указывают на операнды. Глядя на рисунок 1, можно и не догадаться, почему он представляет дерево.
Существует множество инструментов, включая pgAdmin, которые могут генерировать графическое представление плана выполнения. На рисунке 2 показан возможный вывод. Более компактное представление также полученное в pgAdmin, представлено на рисунке 3.
(В pgAdmin вывод дерева может быть получен в редакторе запросов при щелчке на иконках меню редактора Explain или Explain Analyze. Будет получен вывод плана запроса в текстовом формате и в графическом. Есть также меню для выбора установок, которые вы можете применить.)
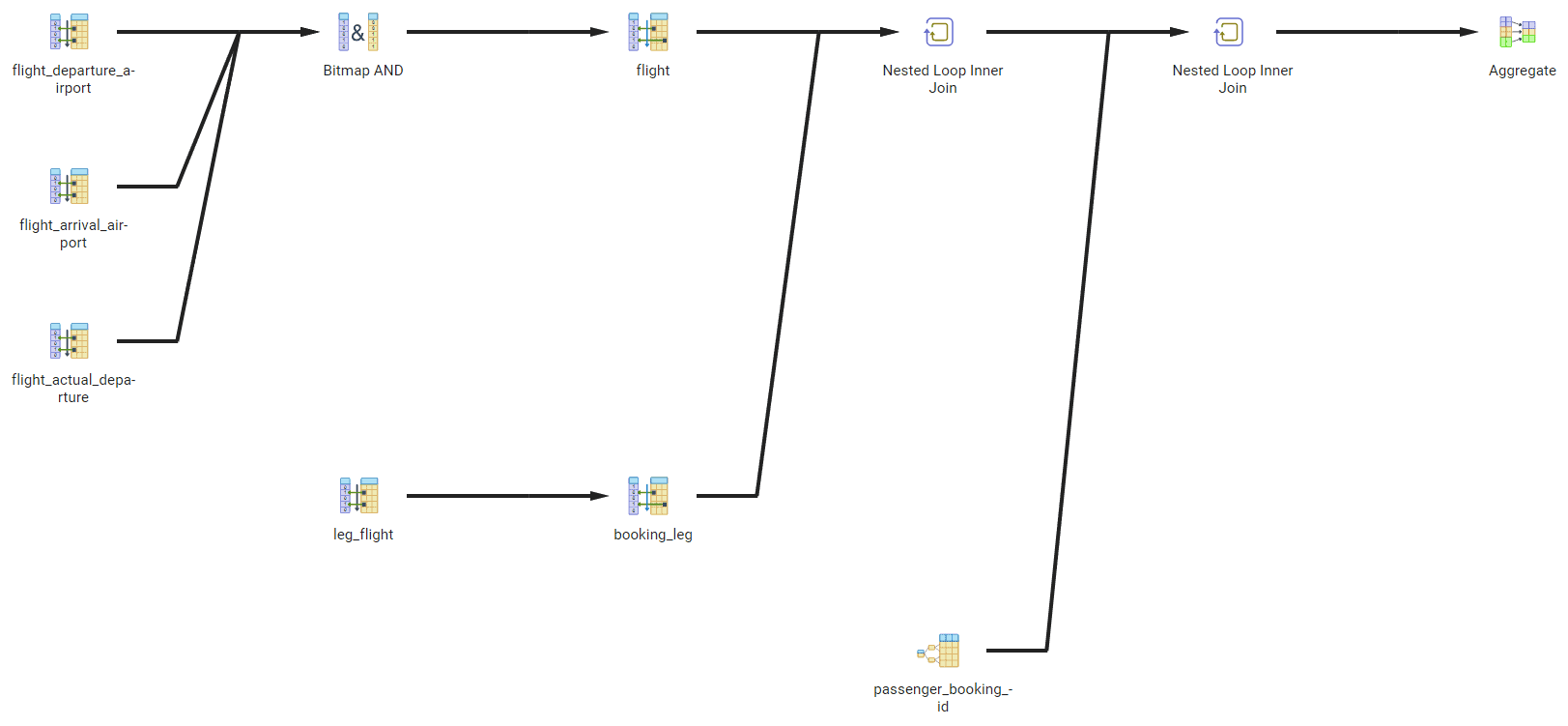
Рис.2. Графический вывод вкладки Explain
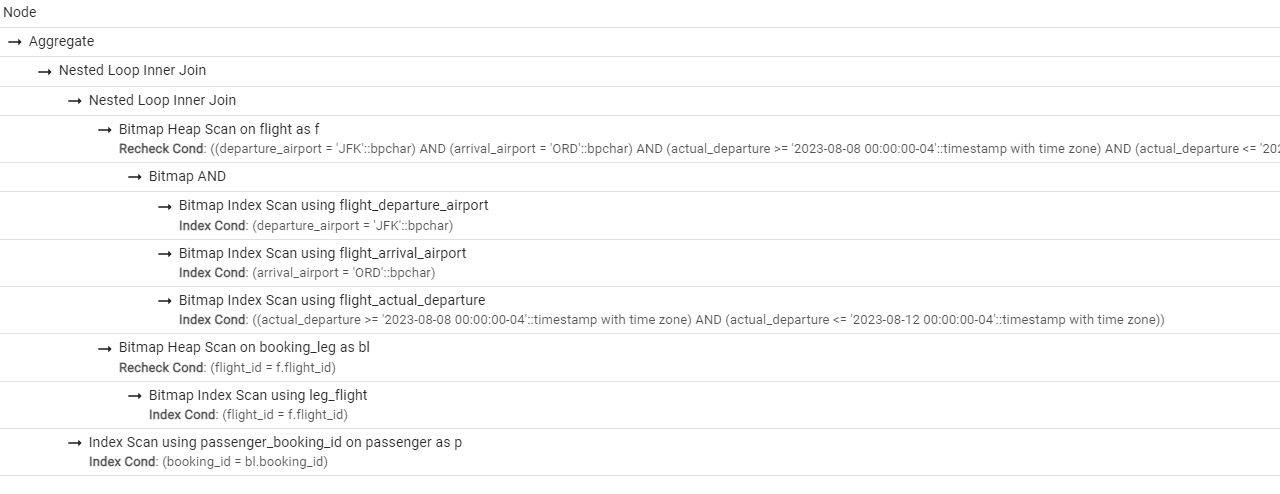
Рис.3. Более компактное представление, находящееся на вкладке Analysis.
Давайте теперь вернемся к фактическому выводу команды EXPLAIN, показанному на рисунке 1. Каждый узел дерева выводится на отдельной строке, начинающейся с ->; глубина узла представляется сдвигом. Поддеревья находятся под родительским узлом. Некоторые операции занимают две строки.
План выполнения стартует с листьев и заканчивается в корне. Это означает, что операция, которая выполняется первой, будет находиться на строке, которая имеет самый большой сдвиг вправо. Конечно, план может содержать несколько листовых узлов, которые выполняются независимо. Как только операция производит выходную строку, она передается следующей операции. Тем самым нет необходимости сохранять промежуточные результаты между операциями.
На рисунке 1 выполнение начинается с последней строки, получая доступ к таблице полетов с использованием индекса на столбце departure_airport. Поскольку к таблице применяется несколько фильтров, а индексом поддерживается только одно из условий фильтрации, PostgreSQL выполняет сканирование побитовой карты индекса. Движок получает доступ к индексу и компилирует список блоков, которые могут содержать необходимые записи. Затем он читает фактические блоки из базы данных с помощью сканирования побитовой карты кучи, и для каждой записи, извлеченной из базы данных, повторно проверяет, что эти строки были получены посредством индекса, и применяет операции фильтрации для дополнительных условий, которых не имеется в индексе: arrival_airport и scheduled_departure.
Результат соединяется с таблицей booking_leg. PostgreSQL использует последовательное чтение для доступа к этой таблице и алгоритм хэш-соединения по условию bl.flight_id = f.flight_id.
Затем осуществляется доступ к таблице passenger посредством последовательного сканирования (поскольку она не имеет никаких индексов), и снова используется алгоритм хэш-соединения по условию p.booking_id = bl.booking_id.
Последней операцией, которая должна быть выполнена, является группировка и вычисление агрегатной функции sum(). Сортировка выведет список всех полетов, которые удовлетворяют критерию отбора (тут их будет четыре). Затем Затем выполняется подсчет всех пассажиров на каждом выполненном полете.
Понимание планов выполнения
Часто, когда мы объясняем, как читать планы выполнения в стиле, описанном выше, наша аудитория испытывает страх перед размером плана выполнения для относительно простого запроса, не говоря уже о том, что более сложный запрос может дать план выполнения, состоящий из 100+ строк. Даже план, представленный на рисунке 1, может потребовать какого-то времени на чтение. Иногда, даже когда каждая и очень простая строка плана может быть интерпретирована, остается вопрос: "У меня есть запрос, и он медленный, а вы говорите мне посмотреть план выполнения, который длиной 100+ строк. Что мне делать? Откуда начинать?"
Хорошей новостью является то, что вам нет необходимости читать весь план, чтобы понять, что именно делает выполнение медленным. В последующих статьях мы обратимся к различным аспектам оптимизации запроса и узнаем, как интерпретировать планы выполнения в каждом случае. Сейчас это может показаться устрашающим, но как только вы поняли несколько основных операций, все прояснится.
Приложение - установка для серии статей
Для этой серии статей, подобно предыдущей, мы будем использовать базу данных, которую я создала для примеров настройки производительности: база данных postgres_air. Если вы хотите повторять эксперименты, описанные в этой статье, загрузите последнюю версию этой базы данных (файл postges_air_2023.backup) и восстановите его на том экземпляре PostgreSQL, где вы планируете выполнять эти эксперименты. Мы предполагаем, что вы будете это делать на своем персональном устройстве или любом другом экземпляре, над которым вы имеете полный контроль, поскольку вам потребуется перезапускать экземпляр пару раз во время этих экспериментов. Мы выполняли примеры на PostgreSQL версии 15.2, однако они будут в целом работать аналогично минимум на версиях 13 и 14.
Восстановление создаст схему postgres_air с данными, но без каких-либо индексов за исключением тех, которые поддерживают ограничения primary/unique. Для повторения примеров вам нужно будет создать пору дополнительных индексов:
SET search_path TO postgres_air;
CREATE INDEX flight_departure_airport ON
flight(departure_airport);
CREATE INDEX flight_arrival_airport ON
flight(arrival_airport);
CREATE INDEX flight_scheduled_departure ON
flight (scheduled_departure);Ссылки по теме
1. Анатомия плана запроса в PostgreSQL
2. Получение плана выполнения запроса в PostgreSQL
3. Типы индексов в PostgreSQL: изучаем PostgreSQL вместе с Grant Fritchey
4. Введение в B-Tree и хэш-индексы в PostgreSQL
5. О применении Hash Match Join
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой