
Улучшить производительность запроса, когда SQL Server игнорирует некластеризованный индекс
Пересказ статьи Mehdi Ghapanvari. Improve Query Performance when SQL Server Ignores Nonclustered Index
Несмотря на наши усилия, направленные на оптимизацию запроса посредством создания некластеризованного индекса, SQL Server, видимо, отдает приоритет сканированию кластеризованного индекса, а не поиску в некластеризованном индексе с последующим поиском ключа. Удивительно, что сканирование кластеризованного индекса оказывается более эффективным для SQL Server в данной конкретной ситуации. Но можем ли мы все же найти способ для улучшения производительности запроса?
Индексирование - один из наиболее важных способов улучшить производительность запроса. Некластеризованный индекс в базе данных предназначен для улучшения производительности запроса путем механизма быстрого поиска. Он отличается от кластеризованного индекса в том, что не определяет физический порядок данных в таблице. Напротив, он устанавливает отдельную структуру, которая содержит индексируемые столбцы и указатели на соответствующие строки данных. Путем индексирования столбцов вы создаете структуру данных, которая позволяет эффективно отыскивать и извлекать информацию из базы данных.
Некластеризованные индексы используют структуру B-Tree. B-Tree - это мощная древовидная структура данных, реализованная в базах данных для оптимизации операций поиска. Название B-Tree происходит от сбалансированной природы дерева, в которой все листовые узлы находятся на одном и том же уровне, а коэффициент ветвления намеренно поддерживается низким, чтобы быстро достигать листовых узлов.
Теперь, когда у нас есть понятие некластеризованных индексов и структуры B-Tree, важно рассмотреть другое важное понятие: переходную точку (tipping point). Переходная точка представляет собой критический порог в планировании запроса, где оптимизатор запросов переключается с использования непокрывающего некластеризованного индекса на выполнение сканирования кластеризованного индекса или кучи. В этой статье я продемонстрирую метод улучшения производительности запроса в случаях, когда SQL Server пренебрегает некластеризованным индексом.
Я буду использовать базу данных StackOverflow и создам индекс на столбце Location в таблице Users. База данных StackOverflow свободно распространяется сайтом StackOverflow.com.
Чтобы получать статистику ввода/вывода, используйте следующую команду:
Выполнив последующий запрос, вы можете получить список пользователей, проживающих в Индии и Германии. Чтобы увидеть фактический план выполнения, просто нажмите Ctrl+M.
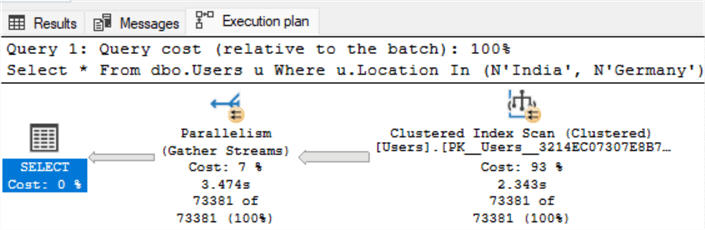
На рисунке ниже можно увидеть, что SQL Server решил проигнорировать некластеризованный индекс и вместо этого выполнил сканирование кластеризованного индекса.
Я хочу протестировать решение, чтобы уменьшить число логических чтений. Следующий скрипт создает временную таблицу и заполняет ее значениями для Индии и Германии.
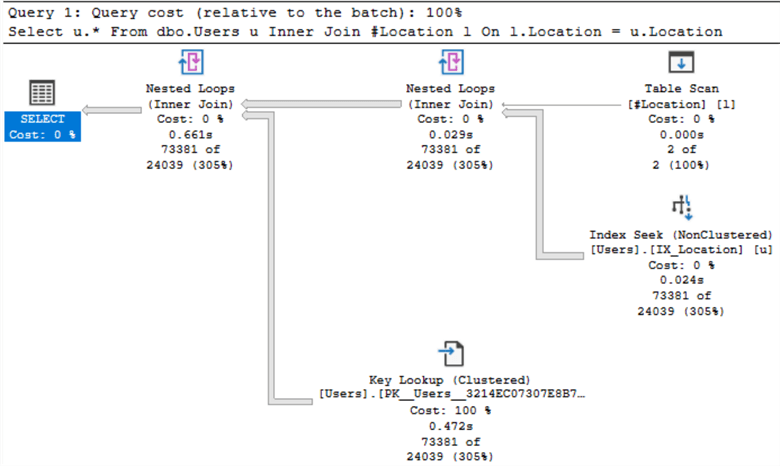
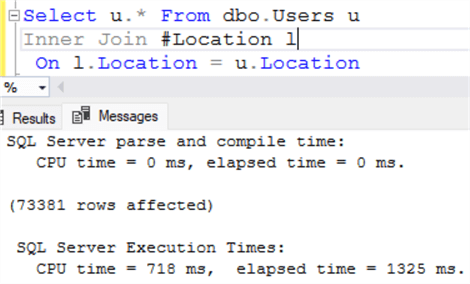
Рисунок ниже показывает, что SQL Server применил операцию поиска в некластеризованном индексе с последующим поиском ключа.
Обратите внимание на число логических чтений, показанных на рисунке ниже.
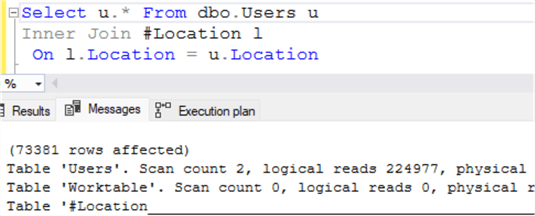
Число логических чтений превышает 224000. Число логических чтений увеличилось. Это оказывает отрицательный эффект на производительность в конкурентной среде.
В SQL Server вы можете использовать оператор SET STATISTICS TIME, чтобы вывести время выполнения оператора T-SQL.
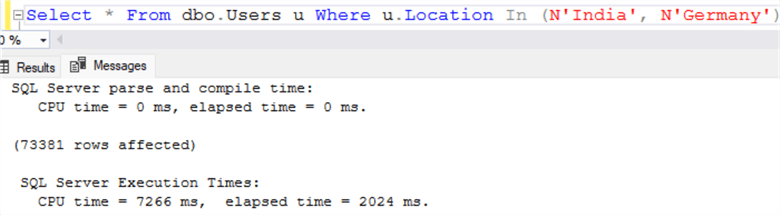
Прошедшее время для операции сканирования кластеризованного индекса отображается на рисунке ниже. Видно, что прошедшее время превышает 2 секунды, а время ЦП превышает 7 секунд.
Ниже можно увидеть прошедшее время, когда SQL Server выполняет операцию поиска в некластеризованном индексе с последующим поиском ключа. Здесь прошедшее время превышает 1300 миллисекунд, а время ЦП превышает 700 миллисекунд.
Один подход приводит к более низким значениям прошедшего времени и времени ЦП, но более высокому числу логических чтений, в то время ка другой - к более высокому прошедшему времени и времени ЦП, но меньшему числу логических чтений.
Важно избегать использования SELECT * и вывода всех столбцов, когда это возможно. Хотя возможно включить все столбцы таблицы в покрывающий индекс, но такая практика не является общепринятой. Это отрицательно влияет на производительность операций DML и увеличивает общий размер таблицы, что делать неразумно. Извлечение небольшого числа столбцов таблицы увеличивает вероятность использования покрывающих индексов. Итак, я собираюсь модифицировать некластеризованный индекс:
Я хочу изменить запрос следующим образом:
На рисунке ниже видно, что SQL Server использует поиск в некластеризованном индексе.
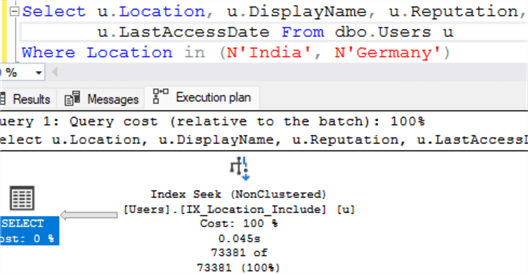
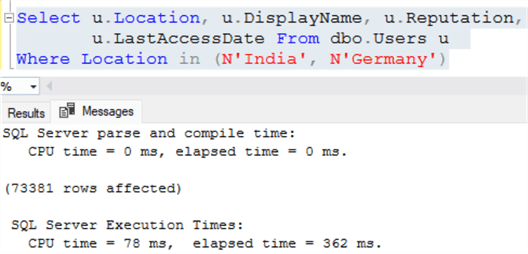
Рисунок ниже показывает, что прошедшее время составляет 362 миллисекунды, а время ЦП 78 миллисекунд. Т.е. коэффициент ускорения составляет около 4х.
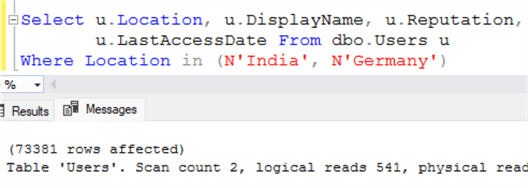
Обратите внимание на число логических чтений. Оно равно всего лишь 541. Изумительно!
Посредством включения всех столбцов, возвращаемых запросом, покрывающий индекс не требует дополнительных чтений для получения данных. Это эффективно снижает число операций ввода/вывода и улучшает производительность запроса. Напомню, что следует избегать включения слишком большого числа столбцов в покрывающий индекс. Важно контролировать индекс после его создания, т.к. SQL Server не гарантирует его использование. Иногда SQL Server может применять некластеризованный индекс, но это может вызвать большое число логических чтений. В общем, избегайте использования SELECT * исключительно ради удобства написания кода.
Индексирование - один из лучших способов улучшить производительность запросов и сократить ввод/вывод. Иногда, несмотря на усилия улучшить производительность запросов путем создания некластеризованного индекса, SQL Server игнорирует индекс и не использует его. Иногда SQL Server может использовать некластеризованный индекс со значительным увеличением числа логических чтений. Одним из возможных решений в этом случае является уменьшение числа столбцов в списке select и использование покрывающего индекса.
Ссылки по теме
1. Типы индексов SQL Server
2. Оптимизатор запросов предлагает неправильный индекс и план запроса - почему?
3. Советы по настройке производительности SQL-запросов
4. Покрывающие индексы SQL Server с ключевыми и неключевыми столбцами для повышения производительности
5. Кучи в SQL Server: часть 3 - некластеризованные индексы
6. Почему не следует использовать SELECT * в рабочих системах (никогда!)
Некластеризованные индексы используют структуру B-Tree. B-Tree - это мощная древовидная структура данных, реализованная в базах данных для оптимизации операций поиска. Название B-Tree происходит от сбалансированной природы дерева, в которой все листовые узлы находятся на одном и том же уровне, а коэффициент ветвления намеренно поддерживается низким, чтобы быстро достигать листовых узлов.
Теперь, когда у нас есть понятие некластеризованных индексов и структуры B-Tree, важно рассмотреть другое важное понятие: переходную точку (tipping point). Переходная точка представляет собой критический порог в планировании запроса, где оптимизатор запросов переключается с использования непокрывающего некластеризованного индекса на выполнение сканирования кластеризованного индекса или кучи. В этой статье я продемонстрирую метод улучшения производительности запроса в случаях, когда SQL Server пренебрегает некластеризованным индексом.
Установка тестовой среды
Я буду использовать базу данных StackOverflow и создам индекс на столбце Location в таблице Users. База данных StackOverflow свободно распространяется сайтом StackOverflow.com.
Use StackOverflow
GO
Alter Database Current Set Compatibility_Level = 160
GO
Create Index IX_Location On dbo.Users (Location)
GOЧтобы получать статистику ввода/вывода, используйте следующую команду:
SET STATISTICS IO ON
GOВыполнив последующий запрос, вы можете получить список пользователей, проживающих в Индии и Германии. Чтобы увидеть фактический план выполнения, просто нажмите Ctrl+M.
Select * From dbo.Users u Where u.Location In (N'India', N'Germany')
GOНа рисунке ниже можно увидеть, что SQL Server решил проигнорировать некластеризованный индекс и вместо этого выполнил сканирование кластеризованного индекса.
Я хочу протестировать решение, чтобы уменьшить число логических чтений. Следующий скрипт создает временную таблицу и заполняет ее значениями для Индии и Германии.
Drop Table If Exists #Location
Create Table #Location ([Location] Nvarchar(100) Collate SQL_Latin1_General_CP1_CI_AS)
Insert Into #Location Values (N'India'), (N'Germany')
GO
Select u.* From dbo.Users u Inner Join #Location l On l.Location = u.Location
GOРисунок ниже показывает, что SQL Server применил операцию поиска в некластеризованном индексе с последующим поиском ключа.
Обратите внимание на число логических чтений, показанных на рисунке ниже.
Число логических чтений превышает 224000. Число логических чтений увеличилось. Это оказывает отрицательный эффект на производительность в конкурентной среде.
В SQL Server вы можете использовать оператор SET STATISTICS TIME, чтобы вывести время выполнения оператора T-SQL.
SET STATISTICS TIME ON
GOПрошедшее время для операции сканирования кластеризованного индекса отображается на рисунке ниже. Видно, что прошедшее время превышает 2 секунды, а время ЦП превышает 7 секунд.
Ниже можно увидеть прошедшее время, когда SQL Server выполняет операцию поиска в некластеризованном индексе с последующим поиском ключа. Здесь прошедшее время превышает 1300 миллисекунд, а время ЦП превышает 700 миллисекунд.
Один подход приводит к более низким значениям прошедшего времени и времени ЦП, но более высокому числу логических чтений, в то время ка другой - к более высокому прошедшему времени и времени ЦП, но меньшему числу логических чтений.
Итак, каково решение?
Важно избегать использования SELECT * и вывода всех столбцов, когда это возможно. Хотя возможно включить все столбцы таблицы в покрывающий индекс, но такая практика не является общепринятой. Это отрицательно влияет на производительность операций DML и увеличивает общий размер таблицы, что делать неразумно. Извлечение небольшого числа столбцов таблицы увеличивает вероятность использования покрывающих индексов. Итак, я собираюсь модифицировать некластеризованный индекс:
Drop Index IX_Location On dbo.Users
Create Index IX_Location_Include On dbo.Users (Location)
Include (DisplayName, Reputation, LastAccessDate)
GOЯ хочу изменить запрос следующим образом:
Select u.Location, u.DisplayName, u.Reputation, u.LastAccessDate From dbo.Users u
Where Location in (N'India', N'Germany')
GOНа рисунке ниже видно, что SQL Server использует поиск в некластеризованном индексе.
Рисунок ниже показывает, что прошедшее время составляет 362 миллисекунды, а время ЦП 78 миллисекунд. Т.е. коэффициент ускорения составляет около 4х.
Обратите внимание на число логических чтений. Оно равно всего лишь 541. Изумительно!
Посредством включения всех столбцов, возвращаемых запросом, покрывающий индекс не требует дополнительных чтений для получения данных. Это эффективно снижает число операций ввода/вывода и улучшает производительность запроса. Напомню, что следует избегать включения слишком большого числа столбцов в покрывающий индекс. Важно контролировать индекс после его создания, т.к. SQL Server не гарантирует его использование. Иногда SQL Server может применять некластеризованный индекс, но это может вызвать большое число логических чтений. В общем, избегайте использования SELECT * исключительно ради удобства написания кода.
Заключение
Индексирование - один из лучших способов улучшить производительность запросов и сократить ввод/вывод. Иногда, несмотря на усилия улучшить производительность запросов путем создания некластеризованного индекса, SQL Server игнорирует индекс и не использует его. Иногда SQL Server может использовать некластеризованный индекс со значительным увеличением числа логических чтений. Одним из возможных решений в этом случае является уменьшение числа столбцов в списке select и использование покрывающего индекса.
Ссылки по теме
1. Типы индексов SQL Server
2. Оптимизатор запросов предлагает неправильный индекс и план запроса - почему?
3. Советы по настройке производительности SQL-запросов
4. Покрывающие индексы SQL Server с ключевыми и неключевыми столбцами для повышения производительности
5. Кучи в SQL Server: часть 3 - некластеризованные индексы
6. Почему не следует использовать SELECT * в рабочих системах (никогда!)
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой