
Соединение больших таблиц в SQL. Как быстро загрузить данные: часть 2
Пересказ статьи Mitchell Warr. Joining Big SQL Tables How to Load Data Fast Part 2
В части 1 мы рассмотрели несколько методов ускорения запросов в PostgreSQL.
Давайте исследуем нашу собственную историю и ускорим запрос. Мы создадим набор таблиц для студентов, классов, преподавателей и посещаемости. Для нашего примера диаграмма ERD будет выглядеть как на рисунке ниже.
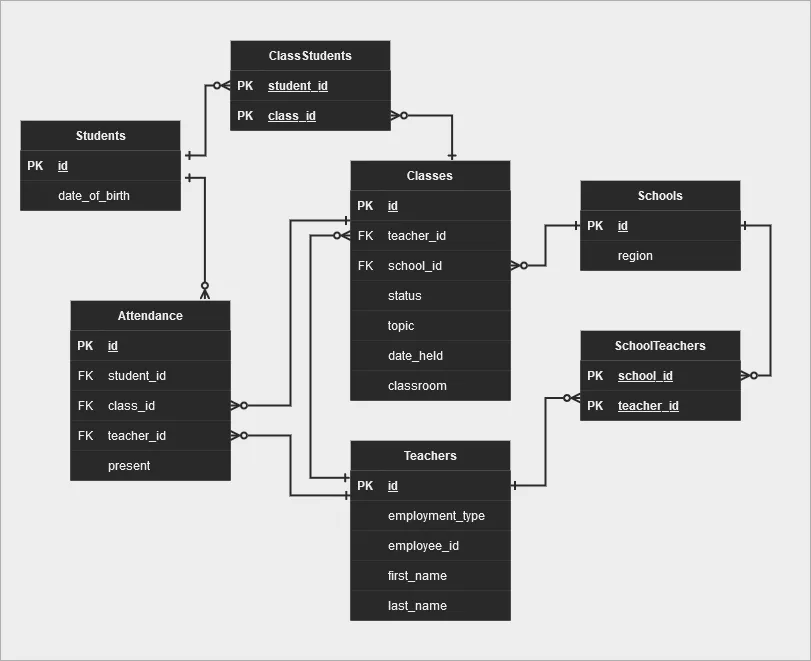
Если каждое занятие представляет собой не весь семестр, а каждое его проведение, то записи о посещаемости и записи о занятиях начинают раздуваться. Учтите также, что это база данных для множества школ; и, вероятно, вся система образования располагает агрегированными данными для принятия управленческих решений.
Как написать запрос и агрегировать таблицу посещаемости (attendance), когда она может быть настолько огромной, и должна включать множество соединений только для того, чтобы ответить на высокоуровневые вопросы относительно посещаемости по регионам школ?
Соединение множества дочерних таблиц
Если вы хотите получить список показателей посещаемости студентов по тематике классов для заданного преподавателя, то можно написать подобный SQL-запрос:
SELECT
classes.topic,
attendance.present,
COUNT(distinct attendance.id) as attendance_count
FROM teachers
INNER JOIN classes ON classes.teacher_id = teachers.id
INNER JOIN class_students ON class_students.class_id = classes.id
INNER JOIN students ON students.id = class_students.student_id
INNER JOIN attendance ON
attendance.student_id = students.id
AND attendance.class_id = classes.id
AND attendance.teacher_id = teachers.id
WHERE
teachers.id = 1263
AND classes.status = 'active'
AND students.date_of_birth > '2010-01-01'
GROUP BY classes.topic, attendance.presentЭто работает, но выполняет множество соединений сложно связанных таблиц. Поскольку таблица посещаемости очень большая, это приведет к увеличению количества строк при каждом их соединении. Соединение таблиц классов и преподавателей было бы очень быстрым и небольшим соединением, но не тогда, когда любая из них также должна быть включена в таблицу посещаемости.
Соединение таблицы посещаемости с этими другими таблицами потребовало бы использования индекса на student_id, class_id и teacher_id для получения уникальной записи. Такой индекс полезен для нахождения отдельной записи, но все же требует обхода каждой строки для их нахождения. Это мало что дает для лучшего предсказания числа строк, которое должно быть получено на выходе этого соединения.
Несколько вещей, которые мы можем сделать для ускорения
Поскольку мы уже знаем, какого преподавателя ищем, мы можем дать планировщику подсказку и поместить teacher_id непосредственно в соединение с посещаемостью. Если порядок в индексе attendance начинается с
teacher_id, то планировщик может получить все строки для этого преподавателя за один проход, благодаря способу, которым индекс хранит строки. Это может быть сделано за несколько миллисекунд, вместо того, чтобы искать каждую запись посещаемости по отдельности, и получить лучшую оценку числа строк.
Мы можем также в этом запросе полностью избавиться от таблицы teachers. Эта таблица используется только для фильтрации по идентификатору преподавателя, что может быть сделано с помощью поля внешнего ключа teacher_id из других таблиц.
Мы можем даже обрезать огромное число строк соединения с таблицей посещаемости, выполнив сначала агрегацию по ИД класса, а затем выполнив соединение с классами. Агрегированный результат имеет небольшое число строк, но мы можем убедиться, что там содержится та же информация. Вы можете подумать, что это еще хуже, поскольку строки посещаемости фильтруются по статусу занятий в соединении, и что агрегирование без фильтра означает, что обрабатывается больше строк.
Это верно, что фильтр уменьшает количество строк, используемых при агрегации. Однако примите в расчет, что:
- Исходное соединение классов с посещаемостью все еще очень большое, и фильтрация происходит во время соединения.
- Соединение фильтровало бы больше строк до агрегации, чем после нее, с тем же самым результатом.
- Агрегация может быть быстрой, когда все уже отсортировано.
- После соединения строки сортируются по ключу соединения, а не по ключу группировки.
В любом случае должен быть выполнен шаг агрегации таблицы посещаемости по множеству строк, но, выполнив агрегацию сначала, вы можете сократить размер на шаге фильтрации и соединения.
Планировщики запросов стараются ограничить число строк на каждом шаге, насколько это возможно, и выберут ту стратегию, которая это делает. Если вы хотите оптимизировать свой запрос, лучше следовать тем же принципам.
Агрегация перед соединением
SELECT
classes.topic,
attendance_grouped.present,
SUM(attendance_grouped.attendance_count) as attendance_count
FROM (
SELECT
attendance.class_id,
attendance.present,
COUNT(*) as attendance_count
FROM attendance
INNER JOIN students ON students.id = attendance.student_id
WHERE
attendance.teacher_id = 1263
AND students.date_of_birth > '2010-01-01'
GROUP BY
attendance.class_id,
attendance.present
) attendance_grouped
INNER JOIN classes ON classes.id = attendance_grouped.class_id
AND classes.teacher_id = 1263
WHERE classes.status = 'active'
GROUP BY classes.topic, attendance_grouped.presentВы можете увидеть, что мы создали двухэтапный запрос. Строки посещаемости группируются в подзапросе FROM. Мы соединяем классы со сгруппированной посещаемостью, что требует добавление этапа суммирования наших количеств.
SELECT SUM(counts)
FROM (
SELECT COUNT(distinct id) as counts
) aПредполагая наличие индекса на classes, который использует teacher_id и включает предложение status = ‘active’, планировщик может использовать этот индекс, если мы добавим classes.teacher_id = 1263 в соединение. Мы сообщаем ему, что таблицы посещаемости и классов связаны по ИД преподавателя, открывая планировщику доступ к индексам.
Планировщик может использовать информацию о связи и индексы для извлечения сразу всех активных классов этого преподавателя, а затем соединить полученные строки. Без этого планировщик может просто использовать индекс на classes_id, после чего выполнить последовательную фильтрацию при соединении. Фильтрация после соединения будет медленней.
INNER JOIN classes ON classes.id = attendance_grouped.class_id
AND classes.teacher_id = 1263
WHERE classes.status = 'active'Проклятие агрегации
Однако следует учесть, что после соединения таблицы посещаемости с таблицей студентов, нельзя полагаться на порядок сортировки таблиц, и планировщик будет выполнять сортировку страниц данных перед их группировкой. Если строк достаточно много, то эта сортировка будет использовать диск. Это процесс медленней и не может использовать индекс.
Было бы лучше, если таблица студентов также соединялась после группировки, тем самым могли быть использованы индексы при сортировке таблицы посещаемости на этапе группировки. Однако нам требуется отфильтровать студентов по дате рождения.
WHERE students.date_of_birth > '2010-01-01'Поскольку наша агрегация подсчитывает уникальные ИД студентов, у нас есть вариант попытаться изолировать таблицу посещаемости. Если ожидается, что отношение студентов к посещаемости близко к один-к-одному, когда имеется один студент на каждую запись посещаемости в нашем множестве, тогда это, вероятно, не даст нам преимущества.
Однако если мы ожидаем, что на каждую строку отдельного студента придется несколько строк посещаемости за определенный семестр, то мы можем сделать следующее:
SELECT
student_attendance.class_id,
student_attendance.present,
SUM(student_attendance.attendance_count) as attendance_count
FROM (
SELECT
attendance.class_id,
attendance.present,
attendance.student_id,
COUNT(*) as attendance_count
FROM attendance
WHERE
attendance.teacher_id = 1263
GROUP BY 1, 2, 3
) student_attendance
INNER JOIN students ON students.id = student_attendance.student_id
WHERE students.date_of_birth > '2010-01-01'
GROUP BY 1, 2Здесь мы можем применить оператор SUM, чтобы сложить все записи для каждого отдельного студента. Агрегация выполнена на одной лишь таблице посещаемости, что означает выбор индексов, отсортированных для группировки. С индексом, подобным нижеприведенному, все должно быть отсортировано и готово к работе.
CREATE INDEX for_attendance_rate ON attendance(
teacher_id, class_id, present, student_id
)Это может оказаться быстрее, но может и нет. Все зависит от коэффициента посещаемости студента, размера таблицы и различия в рабочих строках, действительно ли сильно сокращает количество строк предложение WHERE для таблицы студентов и т.д.
Где еще сократить
Суть ускорения запросов PostgreSQL заключается в том, чтобы всегда брать одну треть от мантры "сокращение, повторное использование, обработка". Если вы хотите поместить этот запрос в быстрый вызов API, то ему может потребоваться разбиение на страницы.
Ссылки по теме
1. Обработка запроса в PostgreSQL
2. Обзор соединений в PostgreSQL
3. Анатомия плана запроса в PostgreSQL
4. Индексы PostgreSQL: что это такое и как они могут помочь
5. Что такое план выполнения и как его найти в PostgreSQL
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой