
Оптимизатор запросов предлагает неправильный индекс и план запроса - почему?
Пересказ статьи Mike Byrd. Query Optimizer Suggests Wrong Index and Query Plan -- Why?
При подготовке презентации на конференцию я наткнулся (случайно) на неожиданный план запроса. Этот план включал предлагаемый индекс, который, к сожалению, и привел к этому очень необычному плану запроса. Данная статья не о том, "как сделать лучше", а, скорее, является началом дискуссии, почему оптимизатор сделал то, что сделал.
Я заглянул в ваши комментарии после прочтения (и, возможно, выполнения кода на ваших компьютерах). Я отправил этот код Майкрософт, но еще не получил подтверждения или какого-либо обсуждения от них.
Посмотрим на то, что я сделал, и какие результаты были получены. Замечу, что этот код выполнялся на SQL Server 2019, CU8.
Используя базу данных AdventureWorks2017, я выполнил следующий запрос (с включением фактического плана выполнения):
И я получаю следующий план (как ожидалось) со стоимостью запроса 0.54456:
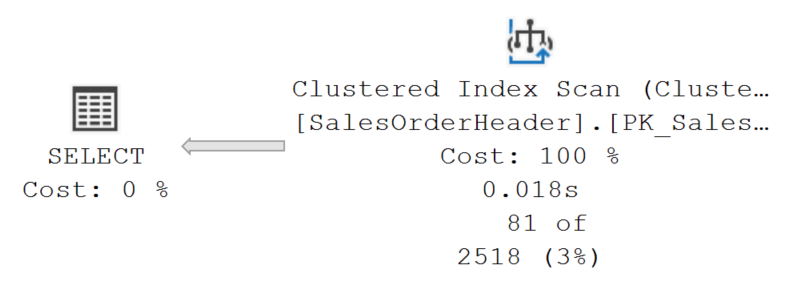
и предлагаемым индексом:

Глядя на executionplan.xml (в аттаче Query1ExecutionPlan.xml), видно предложение отсутствующего индекса и фактические время ЦП 8 мс. Результаты статистики ввода-вывода такие
Если я применю предложенный индекс (ниже)
а затем снова выполню исходный запрос, то получу странно выглядящий план запроса:
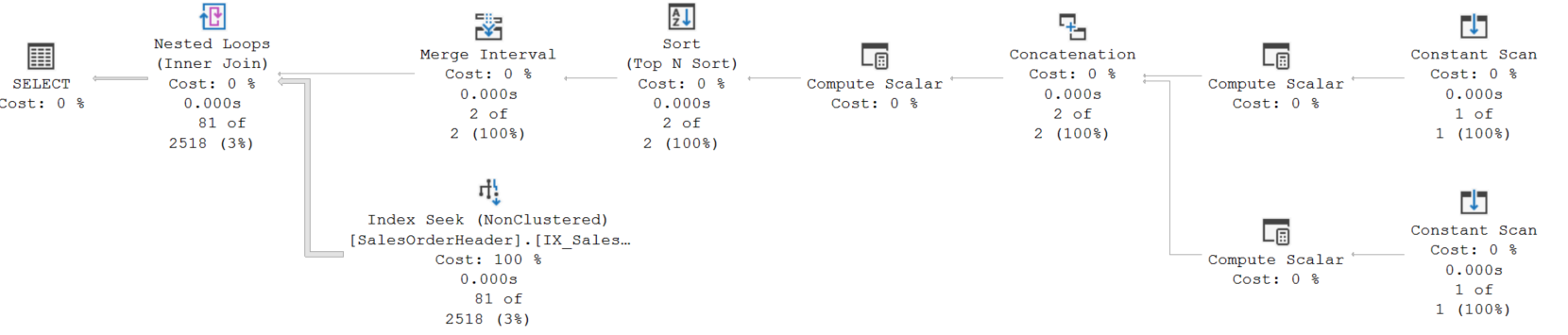
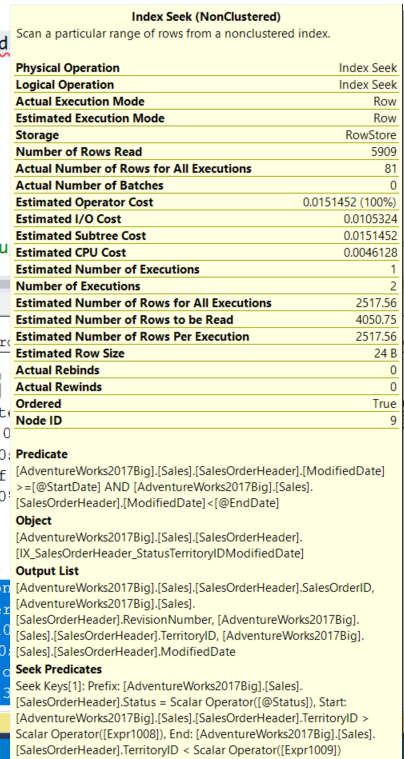
Наведя курсор на IndexSeek, я вижу свойства, представленные на изображении ниже. С поисковым предикатом (Seek Predicate) на Status и TerritoryID, и операцией Predicate с ModifiedDate при полной стоимости запроса 0.045771 и времени ЦП = 3мс (из Query2ExecutionPlan.xml). Что интересно при изучении ExecutionPlan.xml, так это все ссылки на новые столбцы для Expr1008–1013 и связанный с ними xml-код.
Вот статистика ввода-вывода:
И что все показанное ниже означает?

Это один из вопросов, который я вам задаю.
Есть идеи, почему этот код показывает лишнюю логику?
Что еще более интересно, если я переделываю покрывающий индекс, чтобы поменять местами TerritoryID и ModifiedDate в определении столбцов индекса
и повторно выполню исходный запрос, то план выполнения изменится на тот, который я изначально ожидал:

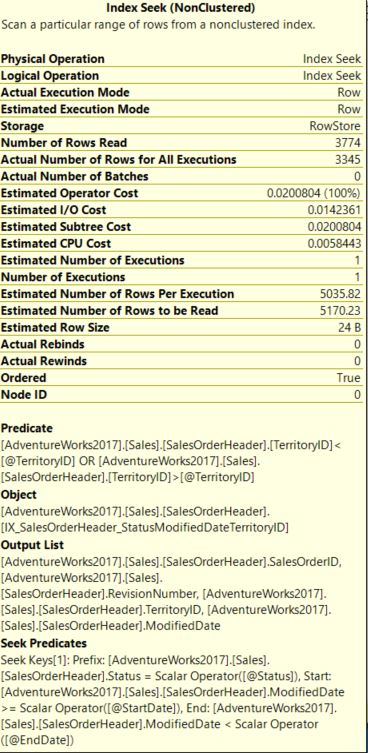
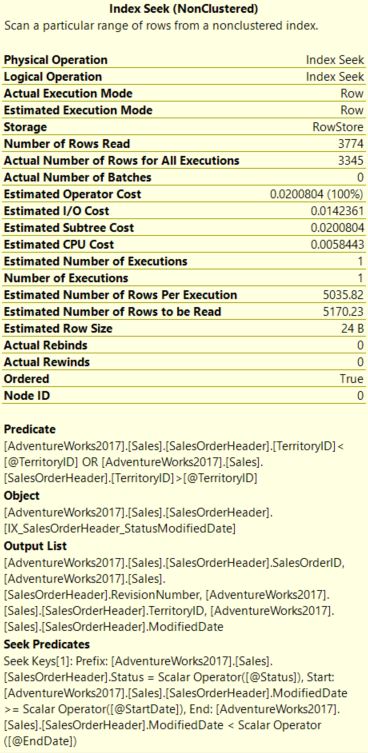
Ниже показаны свойства. С поисковым предикатом на Status и ModifiedDate и операцией Predicate с TerritoryID общая стоимость запроса составляет 0.0200804, и фактическим временем ЦП 2мс (из Query3ExecutionPlan.xml).
Статистика ввода-вывода:
Замечу, что стоимость плана запроса составляет примерно половину стоимости плана исходного запроса с предлагаемым индексом, а логические операции ввода-вывода упали с 87 до 14. Я почти уверен, что оптимизатор находит преимущество от упорядочивания ModifiedDate после проверки на равенство столбца Status для достижения роста производительности.
Для полноты я хочу попробовать еще один сценарий. Давайте модифицируем индекс, оставляя Status и ModifiedDate в определении индекса, но переместим TerritoryID в предложение INCLUDE, как показано ниже:
И теперь после перезапуска запроса (4) мы получаем в точности то, что имели для запроса 3:

С поисковым предикатом на Status и ModifiedDate и операцией Predicate с TerritoryID общая стоимость запроса составляет 0.0200804, и фактическим временем ЦП 2мс (из Query3ExecutionPlan.xml).
Статистика ввода-вывода:
Итак, в запросе 4, поскольку TerritoryID был в Predicate, не имело значения для сканирования Predicate, был ли TerritoryID в определении столбца индекса или в предложении INCLUDE. Хотя для очень большой таблицы наличие TerritoryID в предложении INCLUDE может дать немного меньшее число логических чтений , поскольку TerritoryID находится только на листовом уровне, а не на корневом и промежуточных уровнях B-Tree.
Мы все знаем, что оптимизатор запросов не всегда дает идеальный план запроса, но лишь подходящий. Актуальная терминология исходит из ExecutionPlanXML:
“StatementOptmEarlyAbortReason="GoodEnoughPlanFound"” (причина раннего прекращения оптимизации = найден достаточно хороший план). Поскольку это относительно простой запрос с одной лишь таблицей, я хотел бы узнать, почему он "остановился быстро".
Поэтому еще два вопроса:
Проблема
Посмотрим на то, что я сделал, и какие результаты были получены. Замечу, что этот код выполнялся на SQL Server 2019, CU8.
Используя базу данных AdventureWorks2017, я выполнил следующий запрос (с включением фактического плана выполнения):
SET STATISTICS IO,TIME ON;
DECLARE @StartDate DATETIME = '1/1/2012';
DECLARE @EndDate DATETIME = '1/1/2013';
DECLARE @Status INT = 5;
DECLARE @TerritoryID INT = 6; -- получить все территории кроме Canada
SELECT SalesOrderID, RevisionNumber,TerritoryID, ModifiedDate
FROM Sales.SalesOrderHeader
WHERE ModifiedDate >= @StartDate
AND ModifiedDate < @EndDate
AND [Status] = @Status
AND TerritoryID <> @TerritoryID;
SET STATISTICS IO,TIME OFF;И я получаю следующий план (как ожидалось) со стоимостью запроса 0.54456:
и предлагаемым индексом:
Глядя на executionplan.xml (в аттаче Query1ExecutionPlan.xml), видно предложение отсутствующего индекса и фактические время ЦП 8 мс. Результаты статистики ввода-вывода такие
(3345 rows affected)
Table 'SalesOrderHeader'. Scan count 1, logical reads 689, physical reads 0, …
(1 row affected)
SQL Server Execution Times:CPU time = 16 ms, elapsed time = 223 ms.
Если я применю предложенный индекс (ниже)
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_StatusTerritoryIDModifiedDate
ON Sales.SalesOrderHeader ([Status],TerritoryID,ModifiedDate)
INCLUDE ([RevisionNumber])а затем снова выполню исходный запрос, то получу странно выглядящий план запроса:
Наведя курсор на IndexSeek, я вижу свойства, представленные на изображении ниже. С поисковым предикатом (Seek Predicate) на Status и TerritoryID, и операцией Predicate с ModifiedDate при полной стоимости запроса 0.045771 и времени ЦП = 3мс (из Query2ExecutionPlan.xml). Что интересно при изучении ExecutionPlan.xml, так это все ссылки на новые столбцы для Expr1008–1013 и связанный с ними xml-код.
Вот статистика ввода-вывода:
(3345 rows affected)
Table 'SalesOrderHeader'. Scan count 2, logical reads 87, physical reads 0, …
(1 row affected)
SQL Server Execution Times:CPU time = 0 ms, elapsed time = 150 ms.
И что все показанное ниже означает?
Мой вопрос
Это один из вопросов, который я вам задаю.
Есть идеи, почему этот код показывает лишнюю логику?
Что еще более интересно, если я переделываю покрывающий индекс, чтобы поменять местами TerritoryID и ModifiedDate в определении столбцов индекса
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_StatusModifiedDateTerritoryID
ON Sales.SalesOrderHeader ([Status],ModifiedDate,TerritoryID)
INCLUDE ([RevisionNumber])и повторно выполню исходный запрос, то план выполнения изменится на тот, который я изначально ожидал:
Ниже показаны свойства. С поисковым предикатом на Status и ModifiedDate и операцией Predicate с TerritoryID общая стоимость запроса составляет 0.0200804, и фактическим временем ЦП 2мс (из Query3ExecutionPlan.xml).
Статистика ввода-вывода:
(3345 rows affected)
Table 'SalesOrderHeader'. Scan count 1, logical reads 14, physical reads 0, …
(1 row affected)
SQL Server Execution Times:CPU time = 0 ms, elapsed time = 153 ms.
Замечу, что стоимость плана запроса составляет примерно половину стоимости плана исходного запроса с предлагаемым индексом, а логические операции ввода-вывода упали с 87 до 14. Я почти уверен, что оптимизатор находит преимущество от упорядочивания ModifiedDate после проверки на равенство столбца Status для достижения роста производительности.
Для полноты я хочу попробовать еще один сценарий. Давайте модифицируем индекс, оставляя Status и ModifiedDate в определении индекса, но переместим TerritoryID в предложение INCLUDE, как показано ниже:
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_StatusModifiedDate --move TerritoryID to INCLUDE clause
ON Sales.SalesOrderHeader ([Status],ModifiedDate)
INCLUDE ([RevisionNumber],TerritoryID)И теперь после перезапуска запроса (4) мы получаем в точности то, что имели для запроса 3:
С поисковым предикатом на Status и ModifiedDate и операцией Predicate с TerritoryID общая стоимость запроса составляет 0.0200804, и фактическим временем ЦП 2мс (из Query3ExecutionPlan.xml).
Статистика ввода-вывода:
(3345 rows affected)
Table 'SalesOrderHeader'. Scan count 1, logical reads 14, physical reads 0, …
(1 row affected)
SQL Server Execution Times:CPU time = 0 ms, elapsed time = 152 ms.
Итак, в запросе 4, поскольку TerritoryID был в Predicate, не имело значения для сканирования Predicate, был ли TerritoryID в определении столбца индекса или в предложении INCLUDE. Хотя для очень большой таблицы наличие TerritoryID в предложении INCLUDE может дать немного меньшее число логических чтений , поскольку TerritoryID находится только на листовом уровне, а не на корневом и промежуточных уровнях B-Tree.
Мы все знаем, что оптимизатор запросов не всегда дает идеальный план запроса, но лишь подходящий. Актуальная терминология исходит из ExecutionPlanXML:
“StatementOptmEarlyAbortReason="GoodEnoughPlanFound"” (причина раннего прекращения оптимизации = найден достаточно хороший план). Поскольку это относительно простой запрос с одной лишь таблицей, я хотел бы узнать, почему он "остановился быстро".
Поэтому еще два вопроса:
- Поскольку это "простой" запрос, почему оптимизатор выбрал неверный индекс и неверный план запроса?
- Что это за лишний "мусор", связанный с планом запроса, использующего предложенный индекс?
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой