
Нормализуйте строки для оптимизации пространства и поиска
Пересказ статьи Aaron Bertrand. Normalize strings to optimize space and searches
Эта статья написана для SQL Server, однако эти понятия применимы к любой платформе реляционных баз данных.
Социальная сеть Stack Exchange журнализует большой веб-трафик - даже в сжатом виде мы в среднем имеем свыше терабайта в месяц. И это всего лишь суммарный срез наших общих необработанных данных журнала, который мы загружаем в базу данных для обеспечения безопасности и аналитических целей. На каждый месяц имеется своя собственная таблица, позволяя использовать скользящие окна секционного типа и селективные индексы без дополнительных ограничений и накладных расходов на обслуживание. (Taryn Pratt рассказывает об этих таблицах весьма подробно в своей статье Migrating a 40TB SQL Server Database.)
Не удивительно, что мы имеем такие объемы данных, но можно ли уменьшить их? Давайте взглянем на несколько типичных строк. Хотя это не все столбцы или точные имена столбцов, они должны давать представление, почему 50 миллионов посетителей в месяц только на Stack Overflow могут быстро собраться вместе и наказать наше хранилище:

Теперь представьте аналитиков, выполняющих поиск в этих данных - скажем, поиск по шаблону January 1st для математики и математики на мета. Они весьма вероятно будут писать такое предложение WHERE:
Это вполне ожидаемо ведет к ужасным планам выполнения с остаточным предикатом для поиска совпадения подстроки в каждой строке в диапазоне дат - даже если только три строки соответствуют предикату. Мы можем продемонстрировать это на таблице с некоторым количеством данных:
Теперь выполним следующий запрос (select * для краткости)
И конечно же мы получаем план, который выглядит хорошо, особенно в Management Studio - он содержит поиск по индексу и все! Но это заблуждение, поскольку этот поиск по индексу делает много больше работы, чем следовало. И в реальном мире стоимость этих чтений и других операций много выше, поскольку много строк игнорируется, и каждая строка значительно более широкая.

Что если мы создадим индекс на CreationDate, HostName?
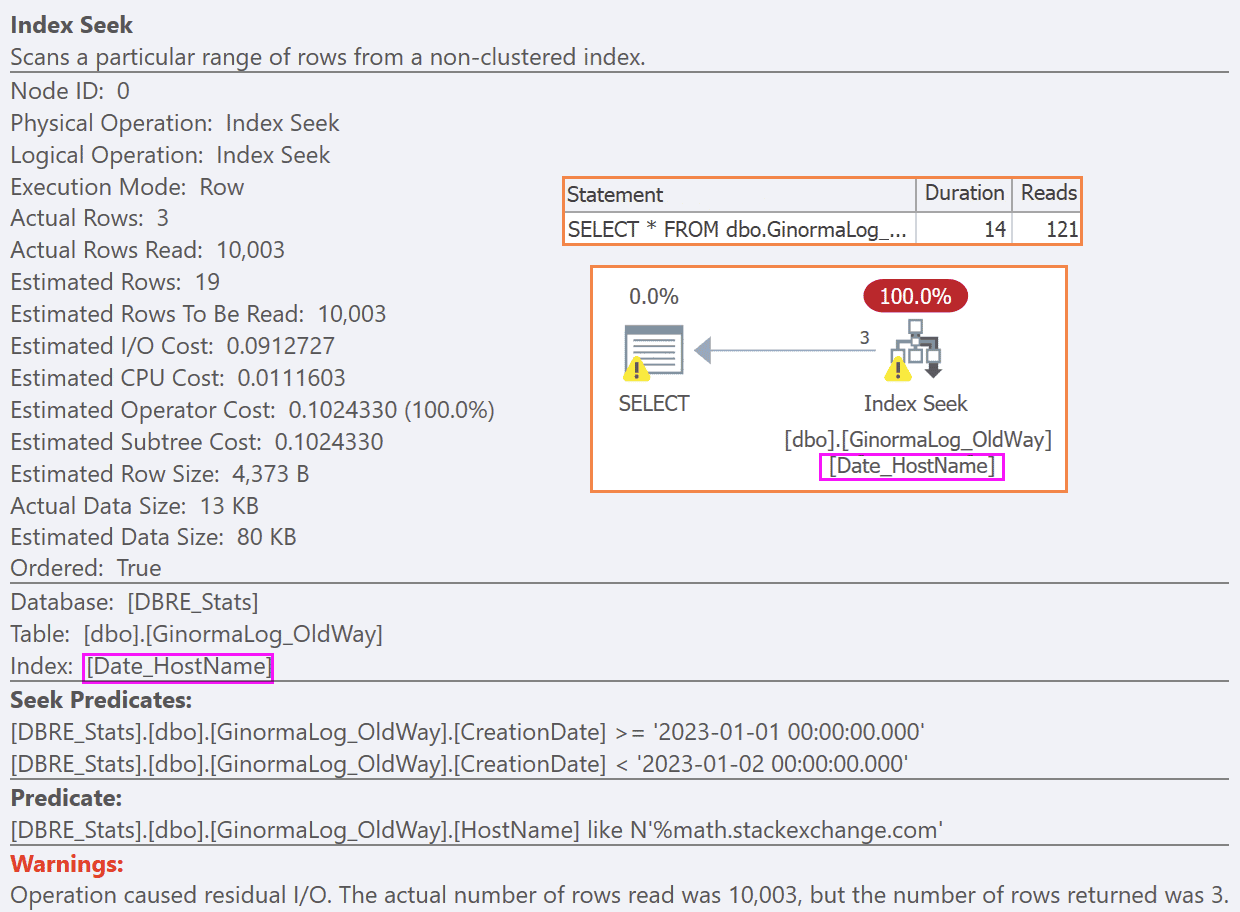
Это не помогает. Мы по-прежнему имеем тот же самый план, поскольку вне зависимости от того, находится ли HostName в ключе, основная масса работы - это фильтрация строк по диапазону дат, после чего проверка строки по-прежнему остается остаточной работой над всеми строками:
Если бы мы могли вынудить пользователей использовать более дружественные к индексам запросы без начальных подстановочных символов, типа этого, мы имели бы больше вариантов:
В этом случае вы можете увидеть, как может помочь индекс на HostName:
Но это будет эффективно, только если вы можете заставить пользователей изменить своим привычкам. Если они продолжают использовать LIKE, запрос будет по-прежнему выбирать старый индекс (и результаты не станут лучше, даже если вы будете принудительно навязывать новый индекс). но с индексом, который первым столбцом использует HostName, и с запросом, который обслуживает этот индекс, результаты значительно лучше:

И это не удивительно, но я хочу отметить, что может быть затруднительным заставить пользователей поменять свои привычки написания запросов и, если вы даже сможете это сделать, может оказаться трудным оправдать создание дополнительных индексов на и без того очень больших таблицах. Это особенно справедливо для таблиц журнала, которые в целом предназначены на запись, только на добавление и изредка чтение.
По мере возможности я бы предпочел создание, в первую очередь, подобных таблиц меньших размеров.
До некоторой степени может помочь сжатие и поколоночные индексы тоже (хотя они потребуют дополнительного рассмотрения). Возможно, вам даже удастся уменьшить размер этого столбца вдвое, убедив свою команду, что имена ваших хостов не обязательно должны поддерживать Unicode.
Любителям приключений я лучше бы посоветовал нормализацию!
Подумайте об этом: если мы журнализуем math.stackexchange.com сегодня миллион раз, имеет ли смысл сохранять 44 байта миллион раз? Я бы сохранил это значение в справочной таблице один раз, когда мы впервые увидели его, а затем использовал суррогатный идентификатор, который может быть значительно меньше. В нашем случае, поскольку мы знаем, что никогда не будем иметь больше 32000 Q&A сайтов, мы можем использовать smallint (2 байта), сэкономив 22 байта на строку (или больше для более длинных имен хостов). Изобразим эту слегка отличную схему:
Затем приложение отображает имя хоста в его идентификатор (или вставляет строку, если не обнаружит его) и вставляет id в таблицу журнала:
Сначала давайте сравним размеры:

Это дает 36% сокращение пространства. Когда мы говорим о терабайтах данных, это может весьма существенно уменьшить стоимость хранилища и значительно продлить использование и время жизни существующего железа.
Как насчет наших запросов?
Запросы несколько усложнились, поскольку теперь мы должны выполнять соединение:
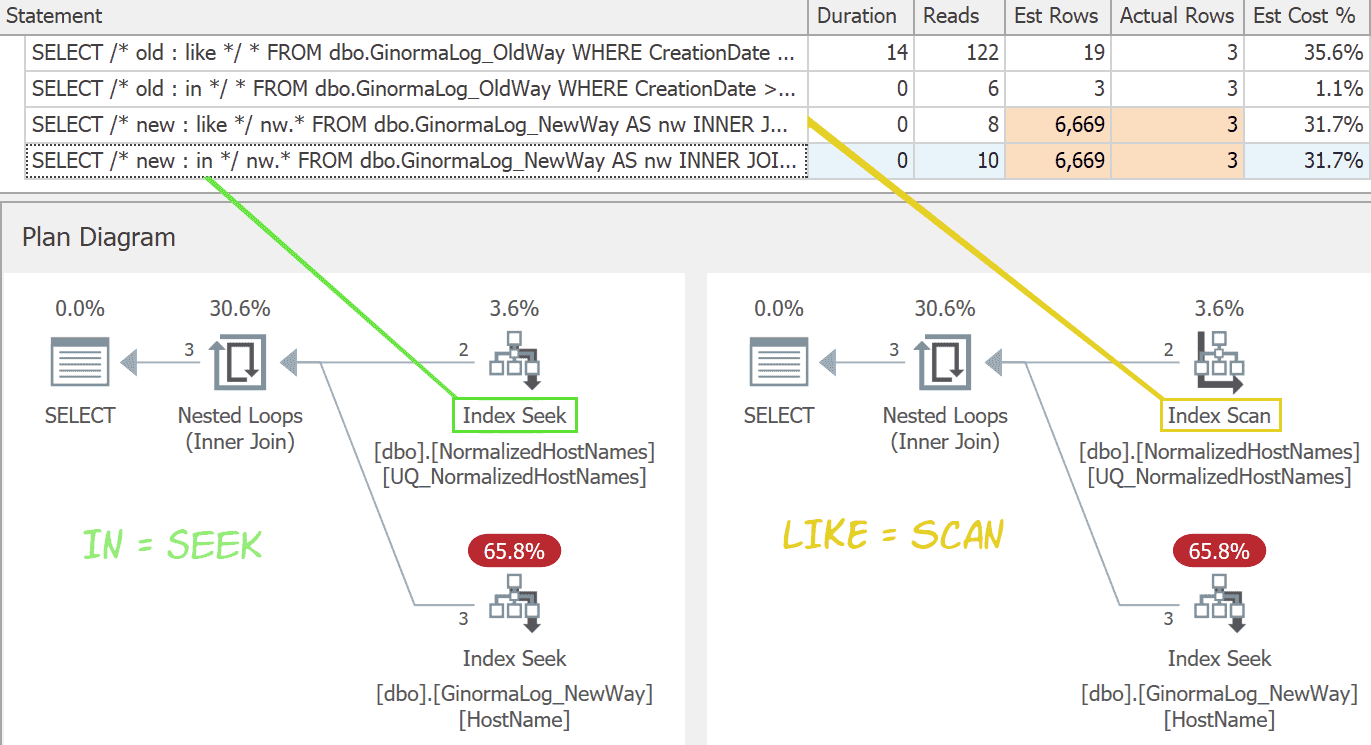
В этом случае использование LIKE не является недостатком, пока таблица имен хостов не станет большой. Планы почти идентичны, за исключением того, что вариация LIKE не может выполнять поиск. (Оба варианта немного хуже оцениваются, но я не понимаю, как в данном случае можно выбрать какой-либо другой план.)
Это один из сценариев, когда разница между поиском и сканированием является настолько небольшой частью плана, что маловероятно окажется существенной.
Эта стратегия все еще требует, чтобы аналитики и другие конечные пользователи немного изменили свои привычки запросов, поскольку им потребуется добавить соединение по сравнению с тем случаем, когда вся информация находилась в одной таблице. Но вы можете сделать это изменение относительно прозрачным для них, предложив представления, которые упрощают соединения:
Никогда не используйте SELECT * в представлении :=)
Выполняя подобный запрос к представлению, мы по-прежнему получим тот же самый эффективный план, который позволит вашим пользователям использовать почти тот же запрос, который они использовали раньше:
Существующая инфраструктура по сравнению с новым проектом
Даже планирование обслуживания для изменения способа записи приложения в таблицу журнала (не говоря уже о фактическом внесении изменений) может оказаться непростой задачей. Это особенно сложно, если журналы заполняются просто массовой вставкой или приходят из множества источников. Может быть имеет смысл использовать новую таблицу (возможно, с секционированием), и начать добавлять новые данные, поступающие в несколько ином формате, оставляя старые данные как есть, используя представление для доступа к ним.
Это может оказаться сложным, и я не упрощаю это изменение. Я хотел об этом написать больше по причине "выученных уроков", если вы строите систему, в которой собираетесь журнализировать множество избыточной строковой информации, подумайте о более нормализированной структуре с самого начала. Значительно проще построить ее таким образом сейчас, чем пытаться сделать это после, когда она может стать слишком большой и будет уже поздно что-либо менять. Просто избегайте обработки всех потенциально повторяющихся строк, т.к. повторений достаточно, чтобы нормализация окупилась. Что касается имен хостов на Stack Overflow, то мы предполагали их ограниченное число, но я бы не стал это предполагать, например, для строк агентов пользователя или ссылочных URL, поскольку эти данные намного более волатильны, и число уникальных значений будет составлять большой процент от всего множества.
Ссылки по теме
1. Проектирование индекса в базах данных и оптимизация: некоторые рекомендации
2. Все, что вам нужно знать о поколоночных индексах, в одной статье
3. Изучение плана запроса в SQL
4. Операторы (итераторы) плана выполнения в SQL Server
Теперь представьте аналитиков, выполняющих поиск в этих данных - скажем, поиск по шаблону January 1st для математики и математики на мета. Они весьма вероятно будут писать такое предложение WHERE:
WHERE CreationDate >= '20230101'
AND CreationDate < '20230102'
AND HostName LIKE N'%math.stackexchange.com';Это вполне ожидаемо ведет к ужасным планам выполнения с остаточным предикатом для поиска совпадения подстроки в каждой строке в диапазоне дат - даже если только три строки соответствуют предикату. Мы можем продемонстрировать это на таблице с некоторым количеством данных:
CREATE TABLE dbo.GinormaLog_OldWay
(
Id int IDENTITY(1,1),
HostName nvarchar(250),
Uri nvarchar(2048),
QueryString nvarchar(2048),
CreationDate datetime,
/* other columns */
CONSTRAINT PK_GinormaLog_OldWay PRIMARY KEY(Id)
);
/* Вставим несколько строк для поиска (иголки) */
DECLARE @math nvarchar(250) = N'math.stackexchange.com';
DECLARE @meta nvarchar(250) = N'meta.' + @math;
INSERT dbo.GinormaLog_OldWay(HostName, Uri, QueryString, CreationDate)
VALUES
(@math, N'/questions/show/', N'', '20230101 01:24'),
(@math, N'/users/56789/', N'?tab=active', '20230101 01:25'),
(@meta, N'/q/98765/', N'?x=124.54', '20230101 01:26');
GO
/* добавим другой реалистичный трафик (стог сена) */
INSERT dbo.GinormaLog_OldWay(HostName, Uri, QueryString, CreationDate)
SELECT TOP (1000) N'stackoverflow.com', CONCAT(N'/q/', ABS(object_id % 10000)),
CONCAT(N'?x=', name), DATEADD(minute, column_id, '20230101')
FROM sys.all_columns;
GO 10
INSERT dbo.GinormaLog_OldWay(HostName, Uri, QueryString, CreationDate)
SELECT TOP (1000) N'stackoverflow.com', CONCAT(N'/q/', ABS(object_id % 10000)),
CONCAT(N'?x=', name), DATEADD(minute, -column_id, '20230125')
FROM sys.all_columns;
GO
/* Создаем индекс, удовлетворяющий многим поискам */
CREATE INDEX DateRange
ON dbo.GinormaLog_OldWay(CreationDate)
INCLUDE(HostName, Uri, QueryString);Теперь выполним следующий запрос (select * для краткости)
SELECT *
FROM dbo.GinormaLog_OldWay
WHERE CreationDate >= '20230101'
AND CreationDate < '20230102'
AND HostName LIKE N'%math.stackexchange.com';И конечно же мы получаем план, который выглядит хорошо, особенно в Management Studio - он содержит поиск по индексу и все! Но это заблуждение, поскольку этот поиск по индексу делает много больше работы, чем следовало. И в реальном мире стоимость этих чтений и других операций много выше, поскольку много строк игнорируется, и каждая строка значительно более широкая.
Что если мы создадим индекс на CreationDate, HostName?
CREATE INDEX Date_HostName
ON dbo.GinormaLog_OldWay(CreationDate, HostName)
INCLUDE(Uri, QueryString); Это не помогает. Мы по-прежнему имеем тот же самый план, поскольку вне зависимости от того, находится ли HostName в ключе, основная масса работы - это фильтрация строк по диапазону дат, после чего проверка строки по-прежнему остается остаточной работой над всеми строками:
Если бы мы могли вынудить пользователей использовать более дружественные к индексам запросы без начальных подстановочных символов, типа этого, мы имели бы больше вариантов:
WHERE CreationDate >= '20230101'
AND CreationDate < '20230102'
AND HostName IN
(
N'math.stackexchange.com',
N'meta.math.stackexchange.com'
);В этом случае вы можете увидеть, как может помочь индекс на HostName:
CREATE INDEX HostName
ON dbo.GinormaLog_OldWay(HostName, CreationDate)
INCLUDE(Uri, QueryString); Но это будет эффективно, только если вы можете заставить пользователей изменить своим привычкам. Если они продолжают использовать LIKE, запрос будет по-прежнему выбирать старый индекс (и результаты не станут лучше, даже если вы будете принудительно навязывать новый индекс). но с индексом, который первым столбцом использует HostName, и с запросом, который обслуживает этот индекс, результаты значительно лучше:
И это не удивительно, но я хочу отметить, что может быть затруднительным заставить пользователей поменять свои привычки написания запросов и, если вы даже сможете это сделать, может оказаться трудным оправдать создание дополнительных индексов на и без того очень больших таблицах. Это особенно справедливо для таблиц журнала, которые в целом предназначены на запись, только на добавление и изредка чтение.
По мере возможности я бы предпочел создание, в первую очередь, подобных таблиц меньших размеров.
До некоторой степени может помочь сжатие и поколоночные индексы тоже (хотя они потребуют дополнительного рассмотрения). Возможно, вам даже удастся уменьшить размер этого столбца вдвое, убедив свою команду, что имена ваших хостов не обязательно должны поддерживать Unicode.
Любителям приключений я лучше бы посоветовал нормализацию!
Подумайте об этом: если мы журнализуем math.stackexchange.com сегодня миллион раз, имеет ли смысл сохранять 44 байта миллион раз? Я бы сохранил это значение в справочной таблице один раз, когда мы впервые увидели его, а затем использовал суррогатный идентификатор, который может быть значительно меньше. В нашем случае, поскольку мы знаем, что никогда не будем иметь больше 32000 Q&A сайтов, мы можем использовать smallint (2 байта), сэкономив 22 байта на строку (или больше для более длинных имен хостов). Изобразим эту слегка отличную схему:
CREATE TABLE dbo.NormalizedHostNames
(
HostNameId smallint identity(1,1),
HostName nvarchar(250) NOT NULL,
CONSTRAINT PK_NormalizedHostNames PRIMARY KEY(HostNameId),
CONSTRAINT UQ_NormalizedHostNames UNIQUE(HostName)
);
INSERT dbo.NormalizedHostNames(HostName)
VALUES(N'math.stackexchange.com'),
(N'meta.math.stackexchange.com'),
(N'stackoverflow.com');
CREATE TABLE dbo.GinormaLog_NewWay
(
Id int identity(1,1) NOT NULL,
HostNameId smallint NOT NULL FOREIGN KEY
REFERENCES dbo.NormalizedHostNames(HostNameId),
Uri nvarchar(2048),
QueryString nvarchar(2048),
CreationDate datetime,
/* другие столбцы */
CONSTRAINT PK_GinormaLog_NewWay PRIMARY KEY(Id)
);
CREATE INDEX HostName
ON dbo.GinormaLog_NewWay(HostNameId, CreationDate)
INCLUDE(Uri, QueryString);Затем приложение отображает имя хоста в его идентификатор (или вставляет строку, если не обнаружит его) и вставляет id в таблицу журнала:
/* вставляем несколько строк для поиска (иголок) */
INSERT dbo.GinormaLog_NewWay(HostNameId, Uri, QueryString, CreationDate)
VALUES
(1, N'/questions/show/', N'', '20230101 01:24'),
(1, N'/users/56789/', N'?tab=active', '20230101 01:25'),
(2, N'/q/98765/', N'?x=124.54', '20230101 01:26');
GO
/* добавляем другой реалистичный трафик (стог сена) */
INSERT dbo.GinormaLog_NewWay(HostNameId, Uri, QueryString, CreationDate)
SELECT TOP (1000) 3, CONCAT(N'/q/', ABS(object_id % 10000)),
CONCAT(N'?x=', name), DATEADD(minute, column_id, '20230101')
FROM sys.all_columns;
GO 10
INSERT dbo.GinormaLog_NewWay(HostNameId, Uri, QueryString, CreationDate)
SELECT TOP (1000) 3, CONCAT(N'/q/', ABS(object_id % 10000)),
CONCAT(N'?x=', name), DATEADD(minute, -column_id, '20230125')
FROM sys.all_columns;Сначала давайте сравним размеры:
Это дает 36% сокращение пространства. Когда мы говорим о терабайтах данных, это может весьма существенно уменьшить стоимость хранилища и значительно продлить использование и время жизни существующего железа.
Как насчет наших запросов?
Запросы несколько усложнились, поскольку теперь мы должны выполнять соединение:
SELECT *
FROM dbo.GinormaLog_NewWay AS nw
INNER JOIN dbo.NormalizedHostNames AS hn
ON nw.HostNameId = hn.HostNameId
WHERE nw.CreationDate >= '20230101'
AND nw.CreationDate < '20230102'
AND hn.HostName LIKE N'%math.stackexchange.com';
/* -- или
AND (hn.HostName IN (N'math.stackexchange.com',
N'meta.math.stackexchange.com')); */В этом случае использование LIKE не является недостатком, пока таблица имен хостов не станет большой. Планы почти идентичны, за исключением того, что вариация LIKE не может выполнять поиск. (Оба варианта немного хуже оцениваются, но я не понимаю, как в данном случае можно выбрать какой-либо другой план.)
Это один из сценариев, когда разница между поиском и сканированием является настолько небольшой частью плана, что маловероятно окажется существенной.
Эта стратегия все еще требует, чтобы аналитики и другие конечные пользователи немного изменили свои привычки запросов, поскольку им потребуется добавить соединение по сравнению с тем случаем, когда вся информация находилась в одной таблице. Но вы можете сделать это изменение относительно прозрачным для них, предложив представления, которые упрощают соединения:
CREATE VIEW dbo.vGinormaLog
AS
SELECT nw.*, hn.HostName
FROM dbo.GinormaLog_NewWay AS nw
INNER JOIN dbo.NormalizedHostNames AS hn
ON nw.HostNameId = hn.HostNameId;Никогда не используйте SELECT * в представлении :=)
Выполняя подобный запрос к представлению, мы по-прежнему получим тот же самый эффективный план, который позволит вашим пользователям использовать почти тот же запрос, который они использовали раньше:
SELECT * FROM dbo.vGinormaLog
WHERE CreationDate >= '20230101'
AND CreationDate < '20230102'
AND HostName LIKE N'%math.stackexchange.com'; Существующая инфраструктура по сравнению с новым проектом
Даже планирование обслуживания для изменения способа записи приложения в таблицу журнала (не говоря уже о фактическом внесении изменений) может оказаться непростой задачей. Это особенно сложно, если журналы заполняются просто массовой вставкой или приходят из множества источников. Может быть имеет смысл использовать новую таблицу (возможно, с секционированием), и начать добавлять новые данные, поступающие в несколько ином формате, оставляя старые данные как есть, используя представление для доступа к ним.
Это может оказаться сложным, и я не упрощаю это изменение. Я хотел об этом написать больше по причине "выученных уроков", если вы строите систему, в которой собираетесь журнализировать множество избыточной строковой информации, подумайте о более нормализированной структуре с самого начала. Значительно проще построить ее таким образом сейчас, чем пытаться сделать это после, когда она может стать слишком большой и будет уже поздно что-либо менять. Просто избегайте обработки всех потенциально повторяющихся строк, т.к. повторений достаточно, чтобы нормализация окупилась. Что касается имен хостов на Stack Overflow, то мы предполагали их ограниченное число, но я бы не стал это предполагать, например, для строк агентов пользователя или ссылочных URL, поскольку эти данные намного более волатильны, и число уникальных значений будет составлять большой процент от всего множества.
Ссылки по теме
1. Проектирование индекса в базах данных и оптимизация: некоторые рекомендации
2. Все, что вам нужно знать о поколоночных индексах, в одной статье
3. Изучение плана запроса в SQL
4. Операторы (итераторы) плана выполнения в SQL Server
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой