
Сила алгоритмов индексирования базы данных: сравнение B-Tree и хэш-индексирования
Пересказ статьи The Java Trail. The Power of Database Indexing Algorithms: B-Tree vs. Hash Indexing
Индексирование базы данных - это критический компонент оптимизации производительности любых систем баз данных. Без эффективного индексирования ваши запросы к базе данных могут стать медленными и неэффективными, что ведет к плохому пользовательскому опыту и падению продуктивности. В этой статье мы изучим некоторые лучшие практики создания и использования индексов базы данных.
Имеется несколько алгоритмов индексирования, используемых в базах данных для улучшения производительности запросов. Вот некоторые из наиболее общих используемых алгоритмов индексирования.
Индексирование B-Tree
Индекс B-Tree является структурой данных в виде сбалансированного дерева, которая хранит отсортированные данные и допускает поиск, последовательный доступ, вставку и удаление в логарифмическое время. Индексная структура B-Tree широко используется в базах данных и файловых системах. Индексирование B-Tree широко используется в реляционных базах данных, таких как MySQL и PostgreSQL.
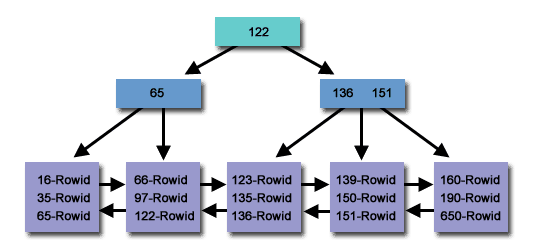
Индексы B-Tree оптимизированы для поиска в диапазоне, поскольку они эффективно находят все записи в диапазоне значений. Это обусловлено тем, что записи сохраняются в индексе в отсортированном порядке. Это дает возможность использовать сравнение столбца в выражениях, с операторами =, >, >=, <, <= или BETWEEN.
Предположим, например, что у нас имеется таблица товаров со следующей схемой:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);Мы можем создать индекс B-Tree на столбце price, используя следующую команду:
CREATE INDEX products_price_index ON products (price);Хэш-индексирование
Хэш-индексирование - еще один популярный алгоритм индексирования, который используется для ускорения выполнения запросов. Хэш-индексы используют хэш-функцию для сопоставления ключей положению в индексе. Этот алгоритм наиболее полезен для запросов на точное совпадение, таких как поиск конкретной записи на основе значения первичного ключа. Хэш-индексирование обычно используется в базах данных, размещаемых в памяти, таких как Redis.
Хэш-индексирование работает путем сопоставления каждой записи в таблице уникальному блоку (бакету) на основе его хэш-значения. Хэш-значение вычисляется с помощью хэш-функции, которая представляет собой математическую функцию, принимающая на входе элемент данных и возвращающая уникальное целое значение.
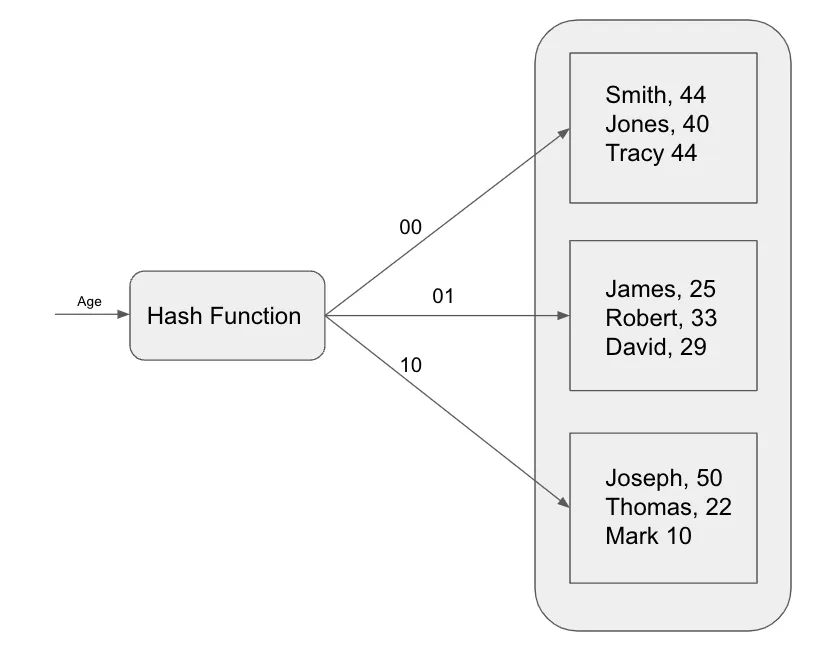
Чтобы найти запись в хэш-индексе, база данных вычисляет хэш-значение ключа поиска, а затем находит соответствующий блок. Если запись находится в блоке, база данных возвращает ее. В противном случае база данных выполняет полное сканирование таблицы.
Хэш-индексы способствуют очень быстрому поиску, но они не могут использоваться для эффективной выборки данных в диапазоне. Это обусловлено тем, что хэш-функция не предусматривает какого либо порядка записей в таблице.
Для выполнения запроса с использованием хэш-индекса
- База данных вычисляет хэш-значение для условия запроса.
- Ищется соответствующий хэш-блок в хэш-таблице.
- Затем база данных извлекает указатель на строки в таблице, которые имеют соответствующее хэш-значение.
- Эти указатели используются для извлечения фактических строк из таблицы данных.
Пусть у нас имеется таблица товаров со следующей схемой:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);Вопрос. Когда хэш-индексирование не оптимизировано, как B-Tree?
Есть ряд сценариев, когда хэш-индексация не является лучшим выбором:
- Хэш-индексы являются более быстрыми, чем древовидные, при поиске на точное совпадение (которое использует операторы = или <=>, но они не могут использоваться для эффективного поиска данных в диапазоне.
- Древовидные индексы медленней при поиске, чем хэш-индексы, но они могут эффективно использоваться для запросов данных в диапазоне.
Запросы в диапазоне. Хэш-индексы для оптимальны для запросов в диапазоне, когда требуется найти записи в пределах диапазона значений (которые используют операторы (=, >, >=, <, <= или BETWEEN). В этих случаях больше подходит индекс B-Tree.
Сортировка. Хэш-индексы не оптимизированы для сортировки, когда вам нужно упорядочить записи на основе конкретного столбца. В таких случаях индекс B-Tree или кластеризованный индекс будут более уместны.
Большие наборы данных. Хэш-индексы могут потреблять большой объем памяти, поэтому они могут не годиться для больших наборов данных, когда использование памяти вызывает проблемы.
Мы можем создать хэш-индекс на столбце name, используя следующую команду:
CREATE INDEX products_name_hash ON products using hash (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';При создания B-tree индекса используется такая команда:
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';Если мы используем хэш-индекс, база данных вычислит хэш-значение поискового ключа “iPhone 13 Pro”, а затем найдет соответствующий блок. Поскольку хэш-функция является детерминированной, база данных всегда будет искать запись в одном и том же блоке, вне зависимости от порядка, в котором записи сохранялись в таблице.
Если мы используем древовидный индекс, база данных начнет поиск с корня дерева, сравнивая поисковый ключ “iPhone 13 Pro” со значением ключа, хранящемся в корне. Поскольку дерево отсортировано, база данных быстро найдет запись, содержащую поисковый ключ.
Вопрос. Почему B-Tree оптимизировано для запросов в диапазоне, а хэш-индекс - нет?
Пусть теперь мы хотим найти все товары с ценой от 100 до 200 долларов. Мы можем использовать следующий запрос:
SELECT * FROM products WHERE price BETWEEN 100 AND 200;Поскольку индексы B-Tree хранят записи в отсортированном порядке, то если поиск ключа в корне дерева не даст результата, база данных определит следующее поддерево на основе результата сравнения с поисковым ключом.
Хэш-индексы устанавливают соответствие для каждой записи в таблице уникальному блоку на основе хэш-значения, которое вычисляется с помощью хэш-функции. Хэш-индексы распределяют данные по блокам случайным образом, делая поиск в диапазоне неэффективным. Получение диапазона значений, подобного ценам от 100 до 200 долларов, потребовало бы сканирования всех блоков в пределах диапазона, что фактически привело бы к полному сканированию таблицы. Хэш-индексы прекрасно выполняют быстрый поиск на точное совпадение, но отсутствие порядка не позволяет их эффективно использовать для поиска в диапазоне.
Почему индекс T-SQL оптимизирован для сортировки, а хэш-индекс - нет?
Индексы B-Tree более эффективны при сортировки данных, чем хэш-индексы, по той причине, что они хранят записи в отсортированном порядке. Это позволяет базе данных быстро перемещаться по записям в порядке сортировки.
Хэш-индексы сопоставляют каждую запись в таблице уникальному блоку на основе хэш-значения. Это означает, что порядок записей в блоках является случайным. Чтобы выполнить сортировку записей, базе данных потребуется пройти по всем блокам, а затем выполнить сортировку. Это более медленно, чем при использовании индекса B-Tree.
Мы можем создать индекс B-Tree на столбце price, используя следующую команду:
CREATE INDEX products_price_index ON products (price); Пусть теперь мы хотим отсортировать товары по цене в порядке возрастания. Мы можем использовать следующий запрос:
SELECT * FROM products ORDER BY price ASC;База данных будет использовать индекс B-Tree для быстрого обхода товаров в порядке сортировки.
Недостатки хэш-индексов:
Хэш-индексация не поддерживает запросы в диапазоне или сортировку.
Хэш-индексы могут потреблять много памяти.
Хэш-индексация не подходит для баз данных, которые часто обновляются.
Битовая (bitmap) индексация
Битовая индексация используется для столбцов с небольшим числом различных значений, таких как логические столбцы или столбцы пола. Битовые индексы очень компактны и эффективны для столбцов с низкой селективностью.
SELECT * FROM employees WHERE gender = 'Female';Битовая индексация высоко эффективна для столбцов с низкой селективностью, что позволяет быстро выполнять теоретико-множественные операции типа объединения и пересечения, хорошо работает с ad-hoc отчетами и хранилищами данных.
Полнотекстовая индексация
Полнотекстовая индексация используется для индексации больших объемов текстовых данных, таких как документы или веб-страницы. Алгоритм такой индексации разбивает текст на слова или токены и индексирует их таким образом, чтобы обеспечить эффективный поиск. Полнотекстовая индексация наиболее полезна для запросов, которые включают поиск в тексте конкретных слов или фраз. Полнотекстовая индексация обычно используется в поисковых машинах типа Elasticsearch.
Случай использования полнотекстового индексирования в электронной коммерции:
Обладая полнотекстовой индексацией приложения электронной коммерции позволяют быстро выполнять поиск по большим каталогам товаров на базе поискового запроса, вводимого пользователем. Полнотекстовая индексация текста позволяет выполнять поиск по нескольким словам или фразам, включая ошибки орфографии, синонимы и даже связанные понятия. Это облегчает пользователю нахождение нужной информации, даже если он не знает точно название или описание товара.
Пусть, например, заказчик ищет новую пару обуви для бега. Он печатает “running shoes” в поисковой строке. С помощью полнотекстового поиска приложение электронной коммерции может быстро выполнить поиск по всем описаниям, названиям и тегам товаров, чтобы найти все товары, относящиеся к обуви для бега. Результаты поиска будут отсортированы по релевантности, которая определяется частотой вхождения поискового термина в информацию о товаре.
Без полнотекстового индексирования поиск может касаться только названия товара и не будет учитывать другие факторы, которые могут быть релевантны для заказчика, такие как описание товара или теги. Кроме того, поиск может не обладать обработкой ошибок орфографии или связанных понятий, таких как “jogging shoes” или “athletic shoes.”
Предположим, что у нас имеется таблица с именем products и следующими столбцами: id, name, description, и tags.
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);Теперь допустим заказчик ищет “running shoes”. Мы можем использовать следующий запрос для поиска товаров, относящихся к поисковому термину:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC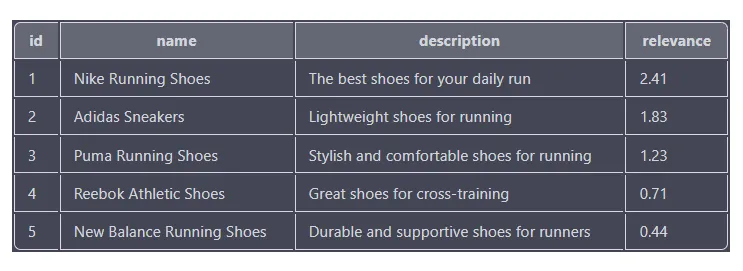
Коэффициент релевантности базируется на том, насколько каждый товар соответствует поисковому термину. Чем больше это число, тем ближе товар к поисковому запросу. Результаты отсортированы в порядке убывания коэффициента релевантности, поэтому товар с наивысшим коэффициентом релевантности (Nike Running Shoes) находится наверху списка.
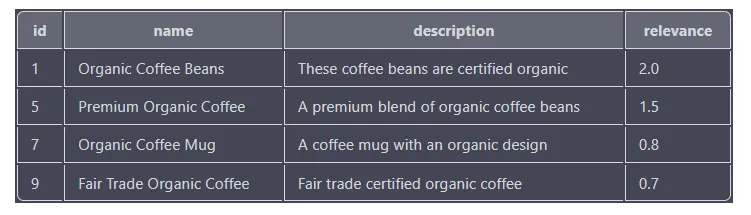
Вот еще один пример поиска товаров, которые содержат слова “organic” and “coffee”:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC; Запрос поиска всех товаров, которые содержат оба ключевых слова “organic” и “coffee” либо в столбцах name, description, либо в столбце tags. Коэффициент релевантности для каждого результата вычисляется на основе числа вхождений и позиции ключевых слов в столбцах.
Вывод должен включать столбцы “id”, “name”, “description” и “relevance” с результатами, отсортированными по столбцу “relevance” в убывающем порядке.
Плюсы:
- Полнотекстовое индексирование очень эффективно для текстовых столбцов.
- Хорошо подходит для поисковых машин и систем управления контентом.
- Поддерживает ранжирование результатов поиска по релевантности.
Минусы:
- Полнотекстовая индексация может потреблять много места в хранилище.
- Производительность может падать при очень больших наборах данных.
- Полнотекстовая индексация не подходит для числовых или категориальных данных.
Ссылки по теме
1. Типы индексов SQL Server
2. Типы индексов в PostgreSQL: изучаем PostgreSQL вместе с Grant Fritchey
3. Индексы PostgreSQL: что это такое и как они могут помочь
4. Понимание индекса SQL: ключ к быстрому выполнению запросов
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой