data_sync_retry — это логический параметр, по умолчанию выключен (off), и его контекст — postmaster, так что для его изменения требуется перезапуск. Вы почти наверняка никогда его не измените. Он существует как видимый рубец от самого тревожного события, которое сообщество PostgreSQL когда-либо узнало о своих собственных допущениях относительно долговечности, и чтобы объяснить этот единственный параметр, нам придётся объяснить fsyncgate.
В чём смысл этого параметра? SHOW data_directory_mode сообщает права доступа Unix на каталог данных — 0700 или 0750 — и это всё, что он делает. Он доступен только для чтения; вы не можете его установить. И он сообщает факт, который ls -ld $PGDATA сообщил бы вам не хуже. Так зачем же он нужен как GUC?
data_directory указывает расположение каталога данных кластера — того самого каталога, который подразумевают под $PGDATA, содержащего base/, pg_wal/, global/ и всё остальное. Контекст — postmaster: параметр можно задать в postgresql.conf или в командной строке, но никогда во время работы. И, как и небольшое число других параметров, его нельзя установить через ALTER SYSTEM — по очевидной причине: ALTER SYSTEM записывает изменения в postgresql.auto.conf, который находится внутри каталога данных, то есть внутри того самого объекта, который вы пытаетесь указать. Нельзя использовать файл внутри «коробки», чтобы сообщить PostgreSQL, где находится эта коробка.
Эта циркулярная зависимость и составляет всю историю данного параметра, так что давайте разберёмся с ней.
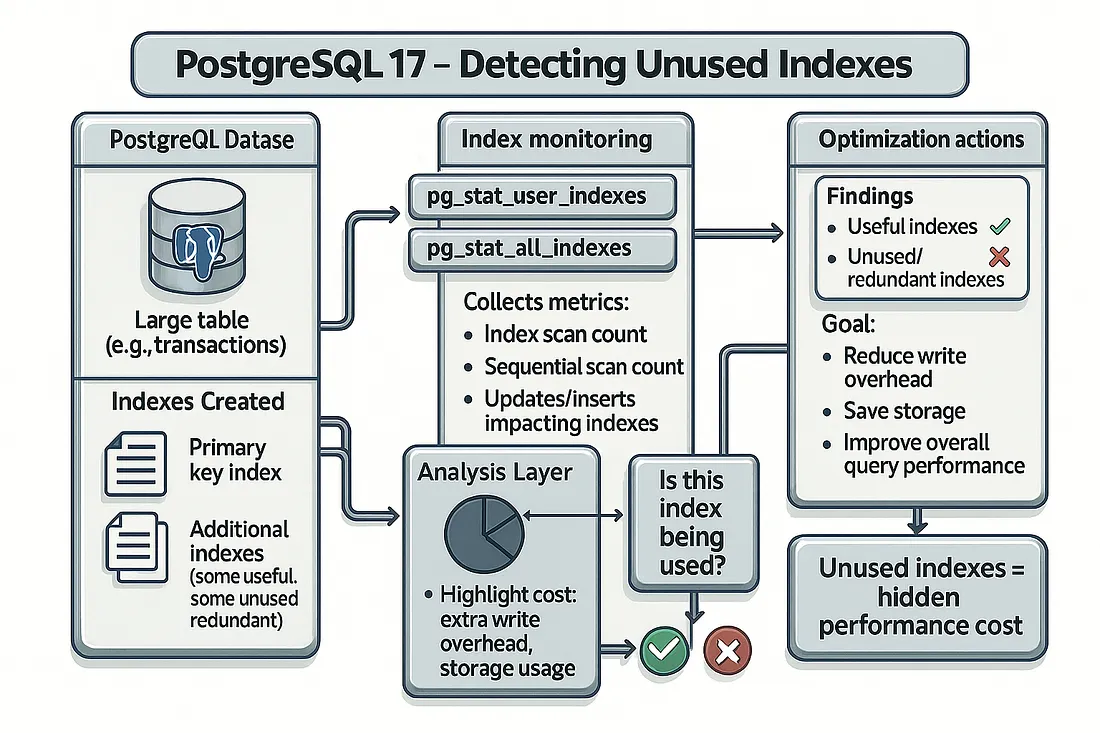
При настройке PostgreSQL большинство разработчиков и администраторов баз данных сосредотачиваются на поиске отсутствующих индексов, чтобы ускорить запросы. Это важный этап, но есть другая сторона медали: иногда вам требуется обнаружить индексы, которых вообще не следует иметь.
Большинство отказов PostgreSQL, связанных с исчерпанием файловых дескрипторов, ошибочно воспринимаются как проблема самой базы данных. Отказ происходит на уровень ниже: ядро исчерпывает файловые дескрипторы, и удар принимает на себя PostgreSQL. В этой статье рассказывается, как это происходит в условиях большого количества подключений, как читать последовательность записей в журнале при возникновении проблемы и как её исправить.
В первой части был изложен основной тезис: pg_stat_statements считает, а не записывает. В ней было показано, как перемешивание queryid разбивает один логический запрос на множество строк, как зафиксированный при первом появлении текст «замораживает» ваши теги на каждый запрос и как усреднённые значения скрывают тот p99, который на самом деле заставляет вас просыпаться по ночам. Всё это касалось данных, которые расширение собирает, но искажает.
Параметр только для чтения, подобно block_size, — команда SHOW data_checksums сообщает, включены ли в кластере контрольные суммы страниц, и это единственное взаимодействие, которое предлагает данный GUC. Но, в отличие от block_size, у этого параметра тринадцатилетняя история, которая всё ещё пишется, и эта история и есть предмет данной статьи.
Большинство параметров стоимости планировщика связаны с моделированием оборудования — насколько дорого чтение случайной страницы, насколько дорог такт ЦП. cursor_tuple_fraction отличается. Он связан с моделированием вас: а именно, с предположением планировщика о том, какую часть результата курсора вы на самом деле собираетесь извлечь.
Расширение pg_stat_statements — если не первое, то одно из самых используемых в экосистеме PostgreSQL. Оно поставляется в составе contrib и практически не требует затрат на использование. Большинство из нас обращаются к нему, чтобы ответить на вопрос: что на самом деле делает база данных? Это действительно полезно. Вы можете использовать его, чтобы получить снимок того, что происходило в заданный интервал времени, и быстрее принять решение о том, что исправлять.
createrole_self_grant — небольшой, недавний (PostgreSQL 16) и почти невозможный для объяснения изолированно. Чтобы рассказать, что он делает, нам нужно поговорить о том, какой была система ролей до 16-й версии, какой она стала сейчас и почему произошли изменения. Этот параметр является одним из видимых артефактов довольно существенного пересмотра, и этот пересмотр интереснее самого параметра.
Мы делали всё правильно. План миграции был надёжным, команда опытной, и мы делали такое и раньше. Но где-то около полуночи кто-то из команды заметил нечто странное. Таблицы на стороне назначения неожиданно разрастались, потребляя сотни гигабайт, в то время как таблицы на исходной стороне спокойно занимали всего несколько мегабайт.
Что-то было серьёзно не так, и мы понятия не имели, что именно.
cpu_tuple_cost, cpu_index_tuple_cost и cpu_operator_cost — это три константы, которые планировщик использует для оценки стоимости запроса. Самое полезное, что можно знать о всех трёх — это то, что вам почти наверняка никогда не следует их менять. Остальная часть статьи объясняет, почему.
constraint_exclusion управляет трюком планировщика: когда таблица имеет ограничение CHECK, планировщик может сравнить это ограничение с условием WHERE вашего запроса и, если они противоречат друг другу, пропустить сканирование таблицы целиком.
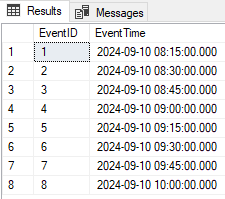
Если вы не много экспериментировали с SQL Server 2022, вы может быть незнакомы с функциями DATE_BUCKET и DATETRUNC. Обе они полезны, когда дело доходит до агрегирования данных. Давайте рассмотрим каждую из этих функций на нескольких примерах.
DATE_BUCKET
Начнем с DATE_BUCKET. DATE_BUCKET дает вам возможность агрегировать данные на основе выбранного вами интервала. Допустим, мы имеем такой набор событий: